Design and Implementation of a Cloud-Native Architecture Based on Microservices Deployed on Kubernetes
1 Introduction
This article covers the implementation of a cloud-native infrastructure deployed on Amazon Web Services (AWS), based on a microservices architecture developed in Go. It also incorporates a CI/CD pipeline that automates the deployment process and ensures high availability, fault tolerance, and service scaling through GitHub workflows and tools such as FluxCD.
The proposed infrastructure represents a common scenario in modern production environments, where microservices-based architectures have largely replaced traditional monolithic systems. In the latter, the application is built as a single unit, which may simplify initial development but introduces limitations as the system grows in complexity. In particular, the accumulation of responsibilities in a single component makes maintenance harder and means a failure can bring down the entire system.
In contrast, in a microservices architecture each component handles a specific piece of functionality and operates independently. This improves system availability since a failure in one service does not cause a total outage. Decoupling between services also makes it easier to evolve the system, add new features, and maintain it over time.
Cloud platforms, compared to traditional on-premises infrastructure, provide resources on demand, enabling scalability, high availability, and simplified infrastructure management. Providers like AWS, Microsoft Azure, and Google Cloud offer managed services that simplify the deployment and operation of distributed applications.
Adopting a cloud-native architecture is challenging, particularly around deployment, infrastructure management, and inter-service communication. Tools like Kubernetes and CI/CD systems help address these challenges.
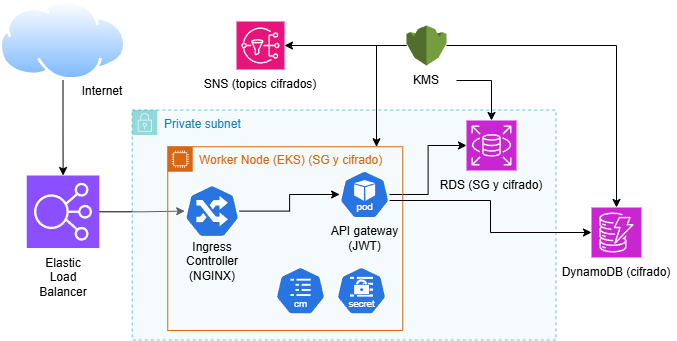
To accomplish this, Terraform is used to provision the cloud infrastructure. On top of it, a Kubernetes cluster is deployed where FluxCD acts as the continuous delivery tool, connected to a GitHub repository containing the manifests needed to deploy and manage the application.
The application itself is a price-tracking tool for products on a given website. It is implemented as a microservices architecture composed of an API, a scraping service, and a serverless task re-scheduling component via AWS Lambda.
Note: This article assumes the reader is familiar with the technologies used in this project.
Note 2: The full thesis will be published on the university website at the end of the month, after the defense. It includes a more detailed explanation of the work for readers with less background in the topic, although it will be in spanish.
2 Development
Before diving in, here is a high-level overview of the system design and the chosen tech stack.
The microservices are developed in Go (Golang), a language designed by Google specifically for scalability and distributed systems problems. It performs close to low-level languages while keeping memory management simple. It is also the de facto standard in the cloud-native ecosystem (Kubernetes itself is written in Go), which ensures optimal integration and efficient container deployment.
The following AWS resources were deployed to support the services:
- Amazon DynamoDB for job storage, and an Amazon Relational Database Service (RDS) PostgreSQL instance for user management. An AWS Lambda function implements the re-scheduler.
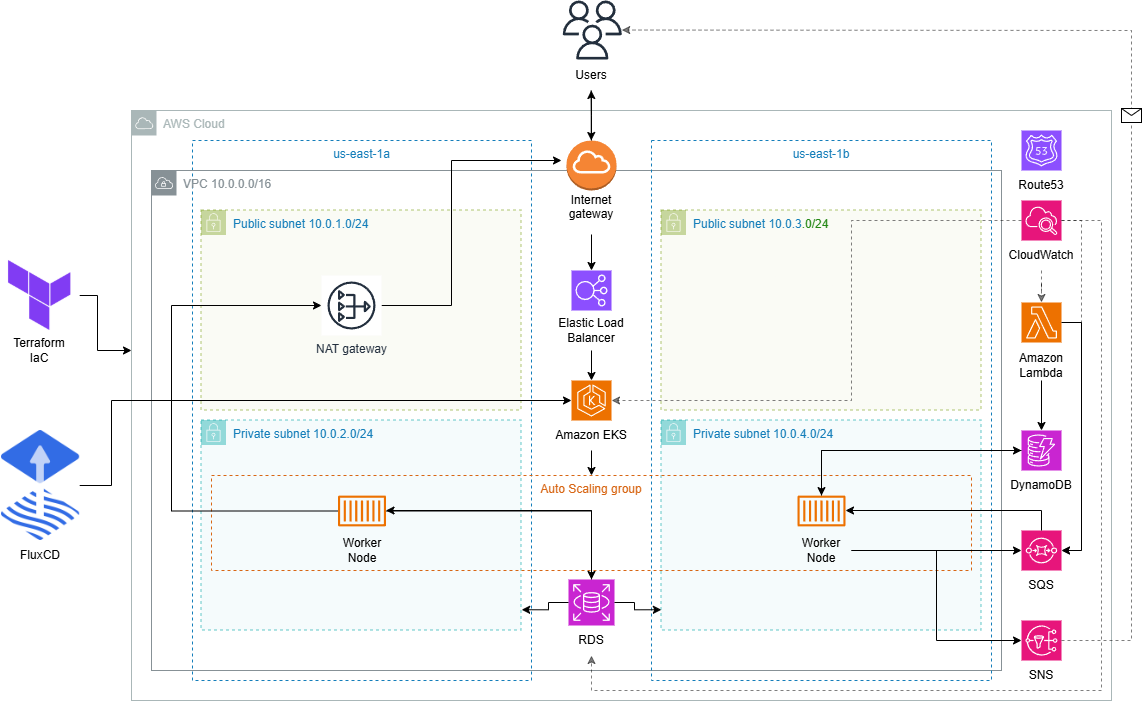
- A Virtual Private Cloud (VPC) encompassing the entire infrastructure, with two public and two private subnets. The main resources (EKS cluster, RDS) live in the private ones. The setup includes routing tables, an Internet Gateway, and a NAT Gateway for external connectivity.
- Amazon Simple Notification Service (SNS) for notifying users of price changes.
- Amazon Simple Queue Service for message queue management.
- Amazon CloudWatch for metrics collection and monitoring.
- Amazon Route 53 for DNS management, providing a stable access point for certain infrastructure resources.
- An Amazon Elastic Kubernetes Service (EKS) cluster with FluxCD installed. Using a GitOps approach, FluxCD applies the manifests defined in a GitHub repository and keeps the desired and actual cluster state in sync. The NGINX Ingress Controller exposes the application through an Elastic Load Balancer (ELB) as the external entry point.
The NGINX Ingress Controller is deprecated, with no updates since March 2026. The natural alternative would be the Kubernetes Gateway API.
The diagram below shows the full infrastructure architecture.
Why this stack?
For databases, two solutions were chosen based on the use case: DynamoDB for jobs (simple key-based access, no joins needed) and RDS PostgreSQL for users (relational data with ACID guarantees). Each one where it makes sense.
For messaging, Kafka was ruled out as overkill for this volume, it requires maintaining a dedicated cluster and is designed for millions of events. SQS/SNS is sufficient with no operational overhead. SNS was preferred over SES for notifications because it allows adding extra channels like SMS without changing the architecture.
The re-scheduler was implemented as a Lambda function rather than a Kubernetes pod. Its logic is minimal and runs periodically, so there is no point in keeping a process running 24/7 with no workload.
For orchestration, the choice was between EKS, ECS, and EC2. ECS is simpler but locks you into the AWS ecosystem. EC2 would require managing orchestration manually, which is not viable here. EKS was chosen for its portability, mature ecosystem (FluxCD, NGINX Ingress…), and because it is the standard in professional environments.
Finally, Terraform was preferred over CloudFormation for being provider-agnostic, having a wider module ecosystem, and using a more readable and maintainable declarative language (HCL).
2.1 Microservices
The microservices are developed in Go and deployed on the EKS cluster worker nodes via FluxCD, as described in the CI/CD Pipeline section. The following diagram illustrates how they interact:
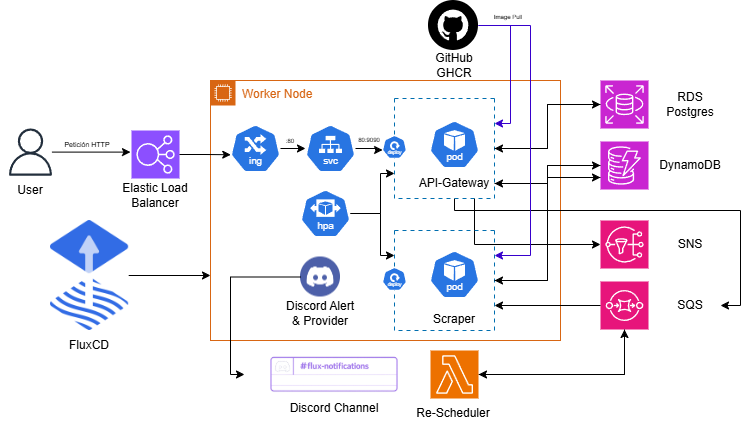
The user registers and logs in through the API Gateway. Once authenticated, they receive a JWT in a cookie granting access to the /validate, /jobs (GET, POST, DELETE), and /jobs/:id endpoints.
Upon registration, the user receives an Amazon SNS email asking them to subscribe in order to receive notifications. When a job is created (a product URL plus a target price), it is enqueued in SQS. The scraper consumes the queue using 5 parallel workers: it extracts the URL and price, scrapes the page, and compares the result with the target price. If the price is at or below the target, the user is notified via email.
The re-scheduler re-enqueues jobs that were processed by the scraper but have not yet reached the target price. Once the scraper deletes the message from the queue, the re-scheduler checks the last recorded price and, if the condition is not met, sends a new message to SQS for the next processing cycle.
The source code for the API Gateway and Scraper is available on GitHub. The re-scheduler code, being a smaller Lambda function, is included in the Appendix.
2.1.1 API Gateway
This microservice was built using Gin, a lightweight Go web framework for REST APIs, along with the AWS SDK for Go.
The application entry point is main.go. Before initializing the router, an init function establishes connections to all external services:
| |
The router and endpoints are configured in the main function:
| |
The API listens on port 9090, accessible externally through the ELB under the /api/v1 prefix. The auth middleware is placed deliberately after the public authentication endpoints.
During registration (/signup), the user sends their credentials, the password is hashed and stored in PostgreSQL, and the user is subscribed to an SNS topic. On login (/signin), the password is validated and a signed JWT is generated:
| |
The auth middleware reads the token from the cookie and validates it:
| |
The DynamoDB data structure for jobs:
| |
Handler tests are run in isolation using mocks for external dependencies, defining an interface that abstracts the PutItem operation:
| |
This allows injecting a mock implementation during tests without real AWS connections.
The repository also includes a GitHub Actions CI pipeline that automates test execution, container image builds, and publishing to GHCR (shown in the microservices diagram).
2.1.2 Scraper
This microservice uses Playwright for browser automation, along with the AWS SDK for Go.
Like the API Gateway, it initializes connections to DynamoDB, SQS, and SNS via an init function before the main logic runs.
The main function defines a concurrent processing strategy with five workers:
| |
Each worker sets the job status to processing before handling it, preventing the re-scheduler from re-enqueuing it prematurely. Extraction is done by launching a headless Firefox browser:
| |
Once the page is loaded, the service navigates to the job URL and locates the title and price selectors based on the domain (Amazon, PCComponentes). If the current price is at or below the target, the job moves to notified and an SNS notification is sent. Otherwise, the status is updated to active and the last observed price is stored for the next cycle.
2.1.3 Lambda Re-Scheduler
The re-scheduler is an AWS Lambda function responsible for re-enqueuing jobs that remain in active state after being processed by the scraper. It scans DynamoDB, identifies jobs that have not yet reached their target price, and sends a new message to SQS.
Its value is not in algorithmic complexity but in the architectural decision to decouple re-scheduling logic from the main scraping process, taking advantage of the serverless model.
2.2 Infrastructure as Code (IaC)
Infrastructure provisioning is automated with Terraform. A key motivation was staying within the AWS Academy Learner Lab budget ($50 limit): with IaC, the entire infrastructure can be spun up and torn down in minutes.
The source code is available in the GitHub repository.
Resources are organized into modules:
| |
These modules provision the resources shown in the diagram below:

Note: Due to scope constraints, the SNS topic, SQS queue, and Lambda re-scheduler were deployed manually. The Learner Lab environment regenerates ARNs each session, making Terraform management of those resources impractical without added complexity.
For the Lambda function, a new instance is created with Amazon Linux 2023 as the runtime and the existing LabRole as the execution role. The function code needs to be compiled first:
| |
The trigger is configured via Amazon EventBridge with a rule that fires every minute, and the required environment variables are added to the function.
For SQS, two parameters are configured: maximum message size (256 KB) and Receive message wait time (20 seconds), to reduce the number of empty responses from the scraper’s continuous polling.
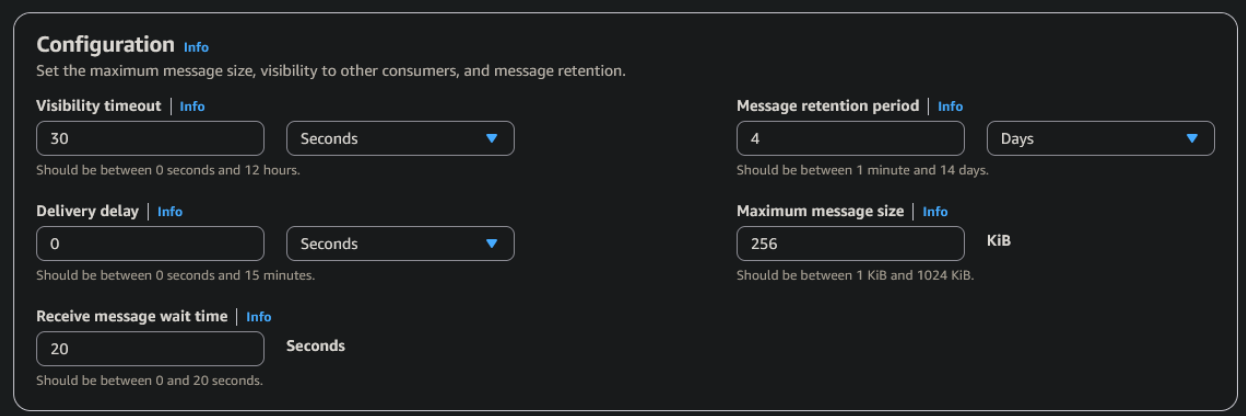
For the SNS topic, a name (PricesNotification) is assigned and encryption is enabled; everything else stays at default.
For the tfstate, in a real environment it would be stored in an S3 bucket with state locking via DynamoDB, using the Cloud Posse tfstate-backend public module:
| |
The VPC is configured with two public and two private subnets across availability zones:
| |
EKS is configured with secrets encryption via AWS KMS:
| |
RDS is configured as not publicly accessible, with a Security Group restricting access to EKS cluster traffic only:
| |
CloudWatch alarms are configured for Lambda errors, RDS/EKS CPU usage, and SQS queue depth, notifying a KMS-encrypted SNS topic:
| |
Route53 exposes a stable alias for RDS (db.dev.internal), so microservice configuration does not need to change when the instance is recreated:
| |
The infrastructure cost estimate, calculated with Infracost, comes to $187/month with all resources running 24/7. In practice, only $19 was spent during development thanks to spinning the infrastructure up and down as needed.
| Module | Resource | Monthly cost (USD) |
|---|---|---|
| eks | EKS Cluster | $73.00 |
| eks | Node Group (2x t3.medium + 40GB gp2) | $64.74 |
| networks | NAT Gateway | $32.85 |
| rds | RDS PostgreSQL db.t3.micro + 20GB gp2 | $15.44 |
| cloudwatch | CloudWatch Alarms (4x standard) | $0.40 |
| route53 | Hosted Zone | $0.50 |
| terraform_state_backend | S3 + DynamoDB (Terraform state) | variable |
| dynamo | DynamoDB jobs table | variable |
| cloudwatch | SNS Topic Alarms | variable |
| Monthly base total | $186.93 |
Resources marked as variable depend on usage (requests, storage, notifications) and have zero or minimal cost in the development environment. The base total corresponds to resources with a fixed price regardless of traffic.
2.3 Kubernetes Orchestration
Kubernetes orchestration relies on Ingress, Services, Deployments, ConfigMaps, Secrets, metrics-server, and HPA, all deployed via FluxCD (see the CI/CD Pipeline section).
The API listens on port 9090, exposed via a ClusterIP Service:
| |
Traffic ingress is managed by the NGINX Ingress Controller, installed via HelmRelease and HelmRepository. The Ingress routes all incoming requests to the API Service:
| |
In values.yaml, the Ingress Controller is configured with a LoadBalancer Service, which triggers automatic ELB creation in AWS:
| |
ConfigMaps are used for non-sensitive configuration variables; Secrets handle sensitive data like AWS credentials or external webhooks.
Secrets are created manually in the cluster and are not committed to the repository:
| |
Three secrets in total: one for the Discord webhook, one for AWS credentials so the microservices can interact with AWS services, and one for the RDS PostgreSQL connection.
A metrics-server is also configured to expose CPU and memory metrics for pods to the Kubernetes API, which is a prerequisite for HPA to function.
2.4 CI/CD Pipeline and Automation
The software lifecycle relies on two complementary mechanisms: GitHub Actions for continuous integration and FluxCD for continuous delivery. GitHub Actions validates code, runs tests, and builds container images; FluxCD implements the GitOps approach on EKS using a Git repository as the single source of truth.
The FluxCD configuration is available in the public flux-repo-tfg repository.
FluxCD is bootstrapped with:
| |
Once bootstrapped, FluxCD deploys and keeps in sync all resources defined in the repository: microservice manifests, internal services, ingress rules, metrics-server, image registry configs, and the objects needed to automate version updates. Some of the deployed components are shown in the microservices diagram.
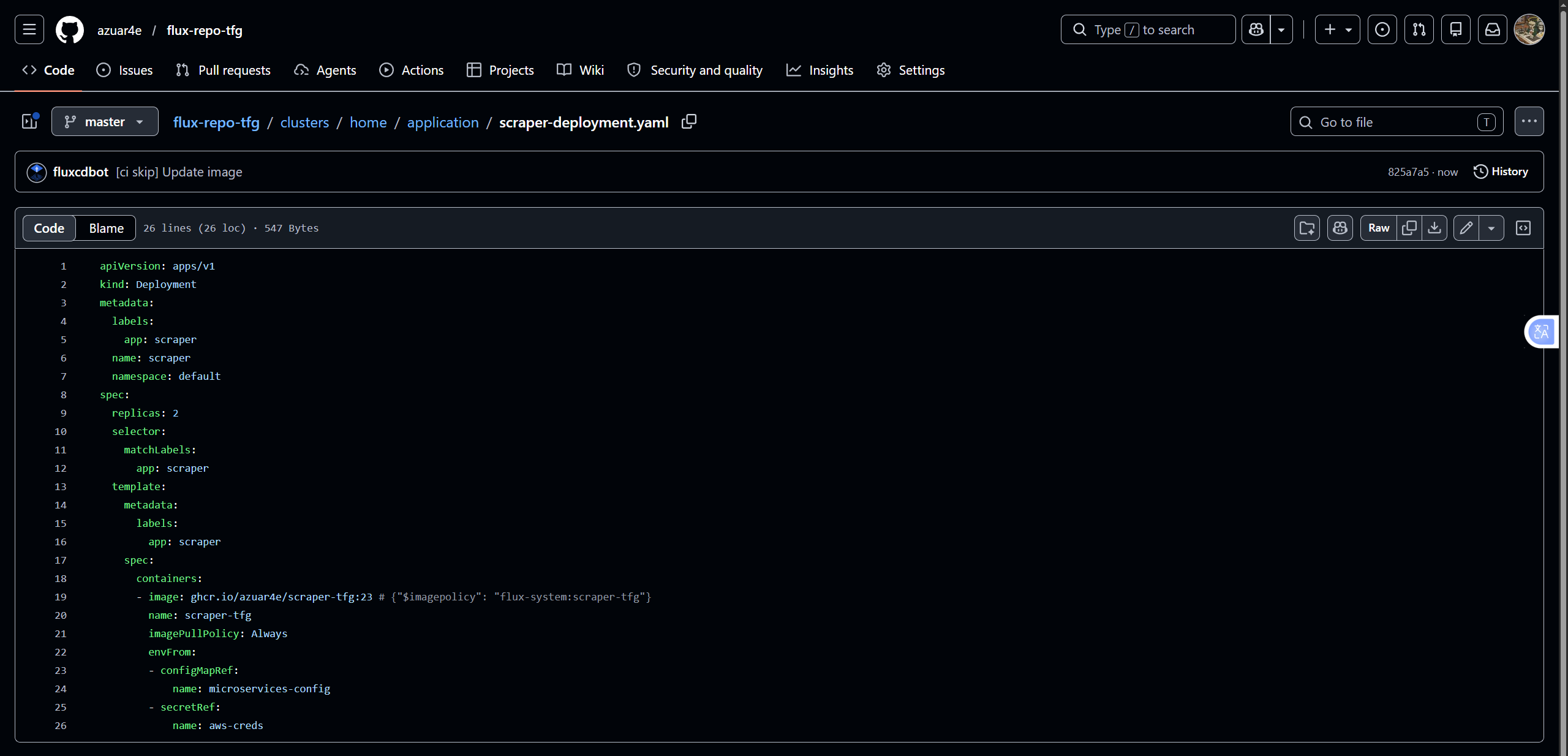
The image auto-update policy:
| |
| |
An ImageUpdateAutomation resource then commits the manifest changes back to the GitOps repository whenever a new valid image version is detected.
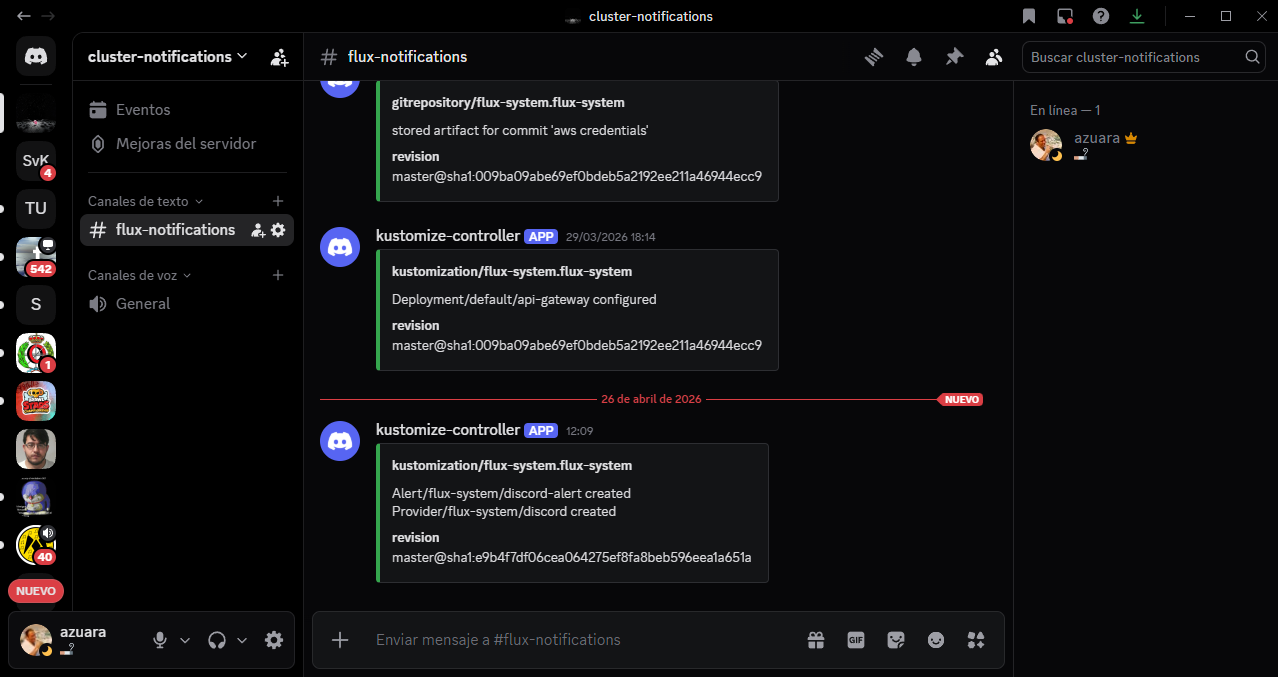
With this setup, pushing to a microservice repository triggers GitHub Actions to build and publish the new image to GHCR; FluxCD detects the new version, auto-commits the updated manifest, reconciles the cluster, and sends a Discord notification.
2.5 Service Communication
Inter-service communication follows an asynchronous, decoupled model. Instead of direct calls between microservices, SQS acts as the intermediary and SNS is the outbound notification channel.
The full flow:
- The user calls the API Gateway, which enqueues the message in SQS.
- The scraper reads from the queue and processes the message.
- If the price target is met, the user is notified via SNS.
- If not, the Lambda scans DynamoDB for
activejobs and re-inserts them into SQS for the next cycle.
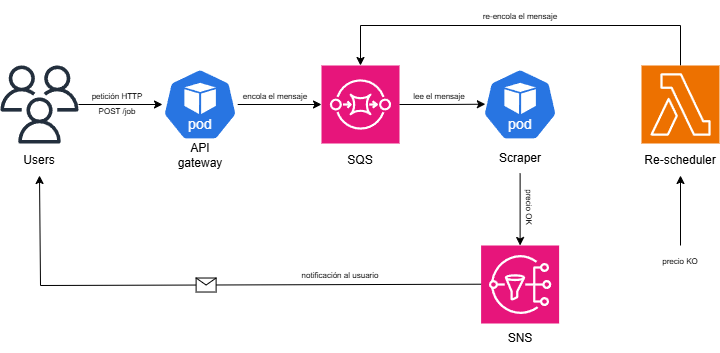
A visibility timeout of 30 seconds is configured in SQS to ensure a message is not consumed by multiple workers simultaneously. The scraper also sets the job status to processing in DynamoDB before handling it, preventing the re-scheduler from re-enqueuing it prematurely.
2.6 Security
Security is split between security-of-the-cloud (AWS’s responsibility: hardware, physical network, hypervisors…) and security-in-the-cloud (the developer’s responsibility):
- At-rest: encryption enabled on RDS PostgreSQL and the DynamoDB table.
- In-transit: as a known limitation, TLS was not configured, so external communications happen over HTTP. Internal pod-to-pod communication also lacks TLS since no service mesh was implemented.
For network filtering, Security Groups on RDS restrict access to traffic coming from the EKS cluster Security Group only:
| |
Application access is controlled through the API Gateway with JWT authentication. At the infrastructure level, the public/private subnet separation ensures only components that need external exposure are reachable from the Internet. All inbound traffic is centralized through the Ingress Controller and ELB, reducing the attack surface.
Kubernetes configuration is managed through ConfigMaps and Secrets, keeping a clean separation between non-sensitive configuration parameters and sensitive credentials.
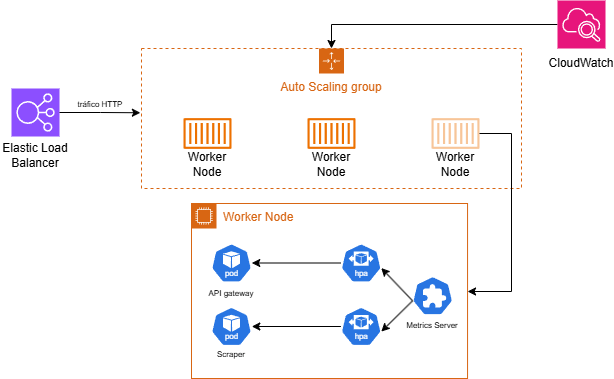
2.7 Scalability and Resources
The system was designed with scalability and efficient resource usage in mind. Two main mechanisms were applied:
- Resource requests and limits on Deployments to prevent a single pod from consuming all node resources.
- HPA for the scraper and the API, dynamically adjusting the number of replicas based on load.
Limits defined for the API:
| |
And for the scraper (adjusted after an OOMKilled during testing):
| |
The HPA was configured with a 50% CPU threshold and a range of 1 to 10 replicas for the API, and 1 to 4 for the scraper. The EKS node group was designed with a minimum of 1 node, a desired count of 2, and a maximum of 3 t3.medium instances (2 vCPUs, 4 GB RAM), with the ability to scale up to 6 cores and 12 GB via the Cluster Autoscaler.
Scaling the scraper by CPU is not ideal since it is an asynchronous service whose load depends on the number of messages in the SQS queue, not HTTP traffic. CPU is used as a proxy metric given the lack of a custom-metrics-based HPA. A future improvement would be adopting KEDA to scale based on SQS queue depth.
3 Validation and Testing
This section validates the correct behavior of the system, both at the functional level and from an infrastructure and deployment automation perspective.
3.1 API Functional Validation
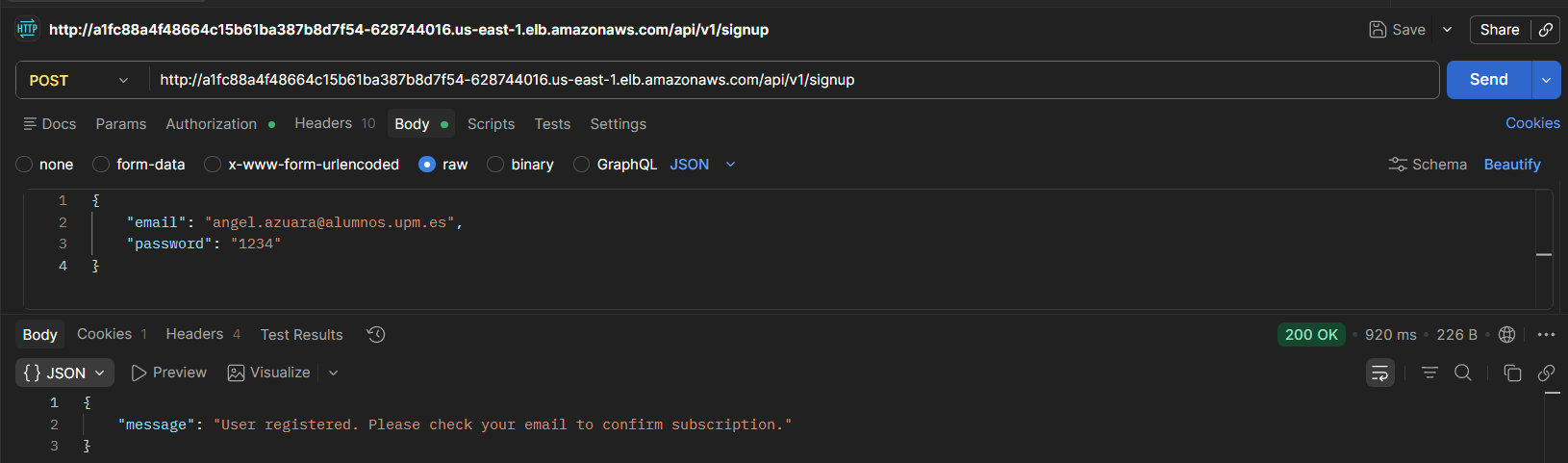
3.1.1 Endpoint /signup
The API correctly registers a new user.
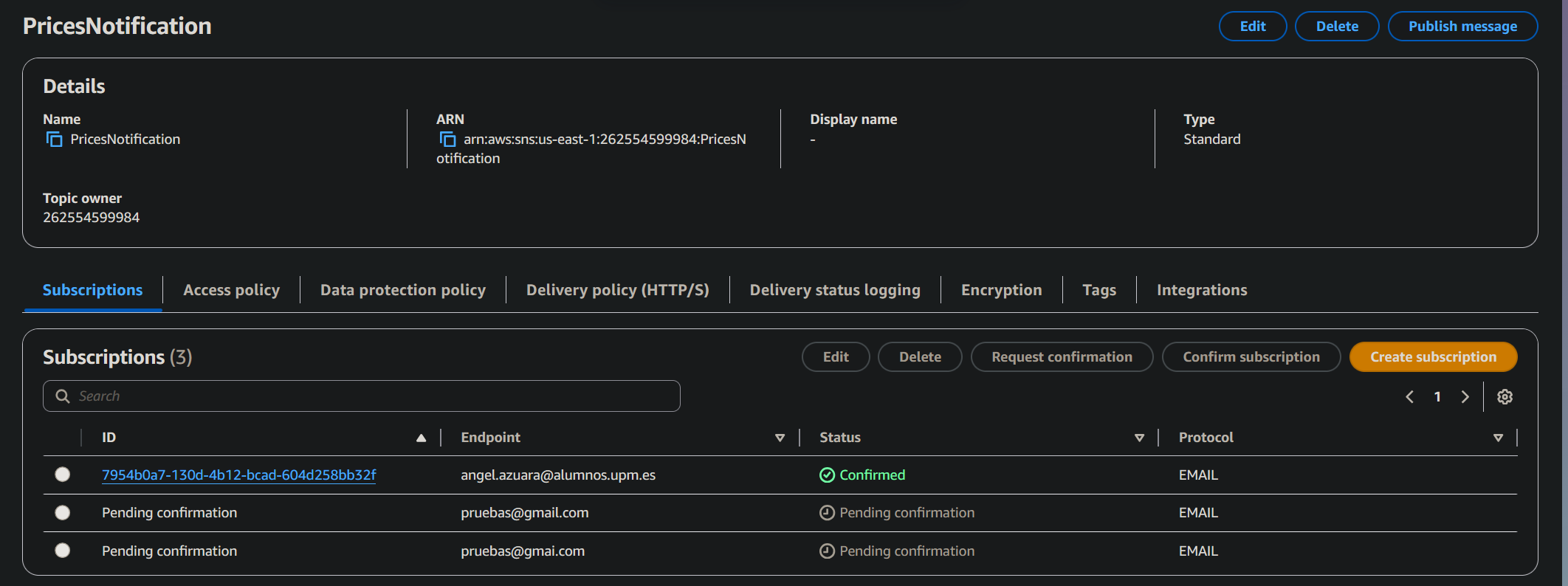
After registration, the API automatically subscribes the user to an SNS topic, triggering a confirmation email.
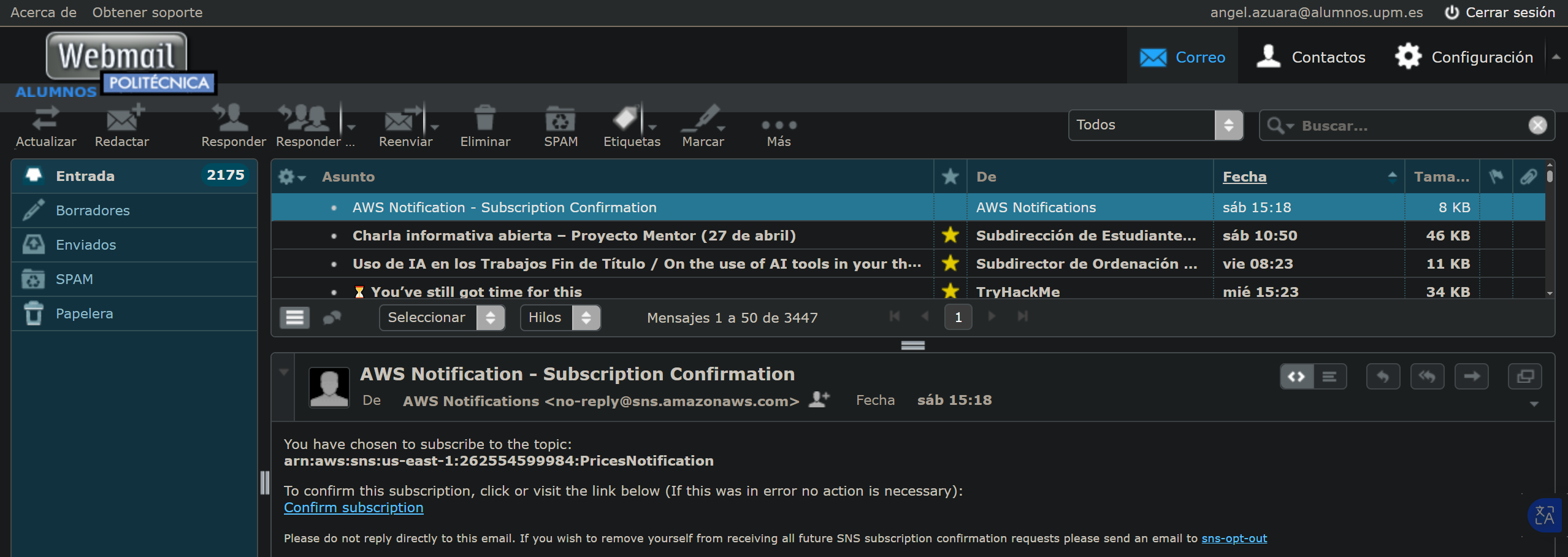
The user is listed as a subscriber once the invitation is accepted.
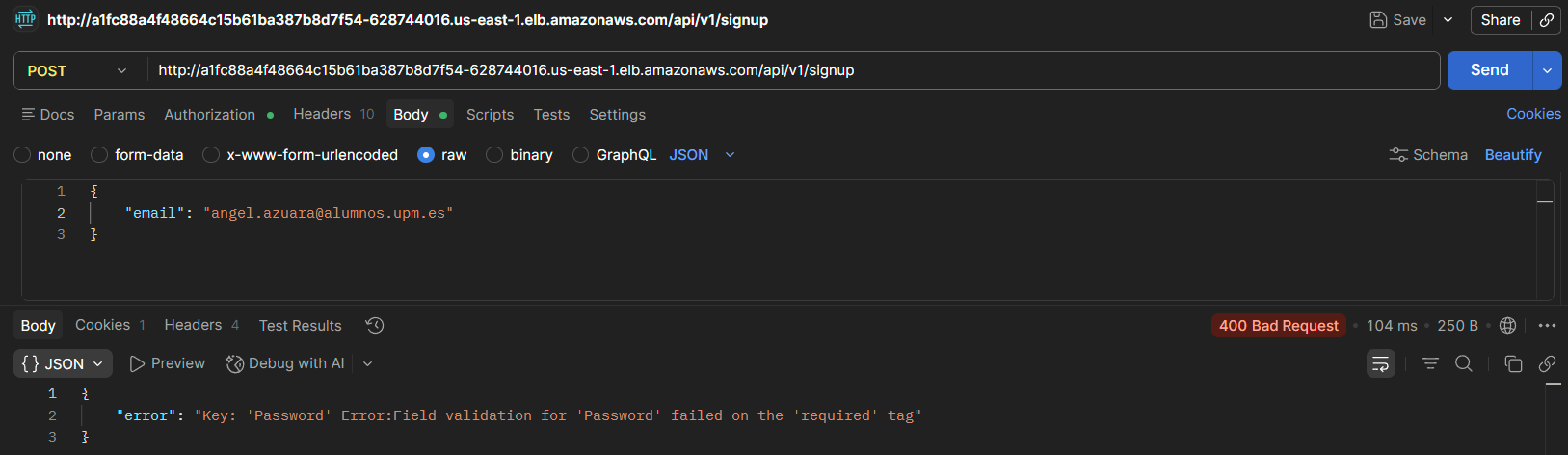
Error handling was also validated, such as a missing password field.
3.1.2 Endpoint /signin
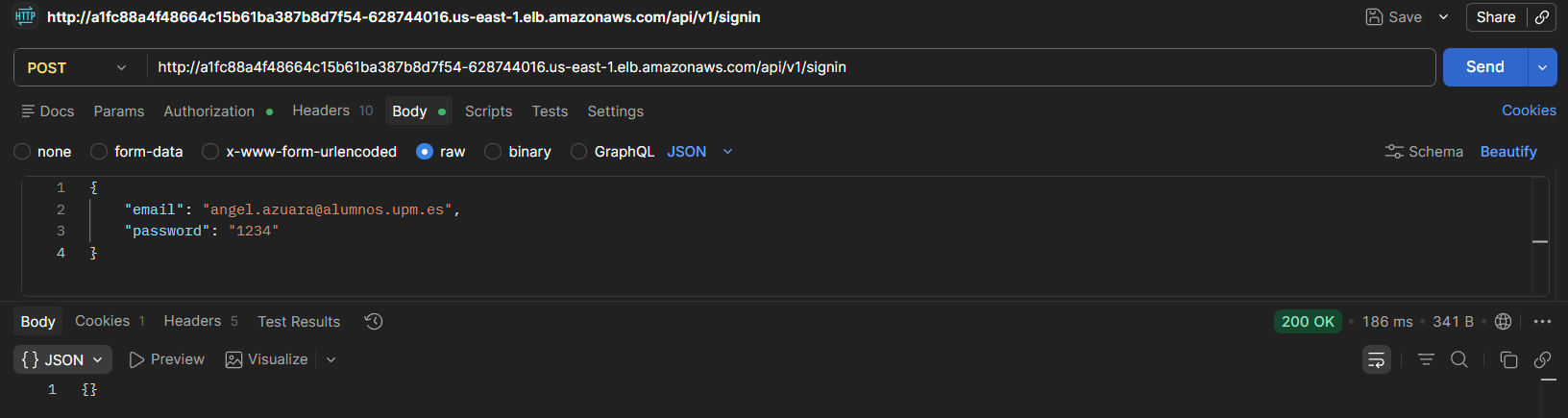
The API correctly authenticates a user with valid credentials, generating a cookie containing the JWT token.

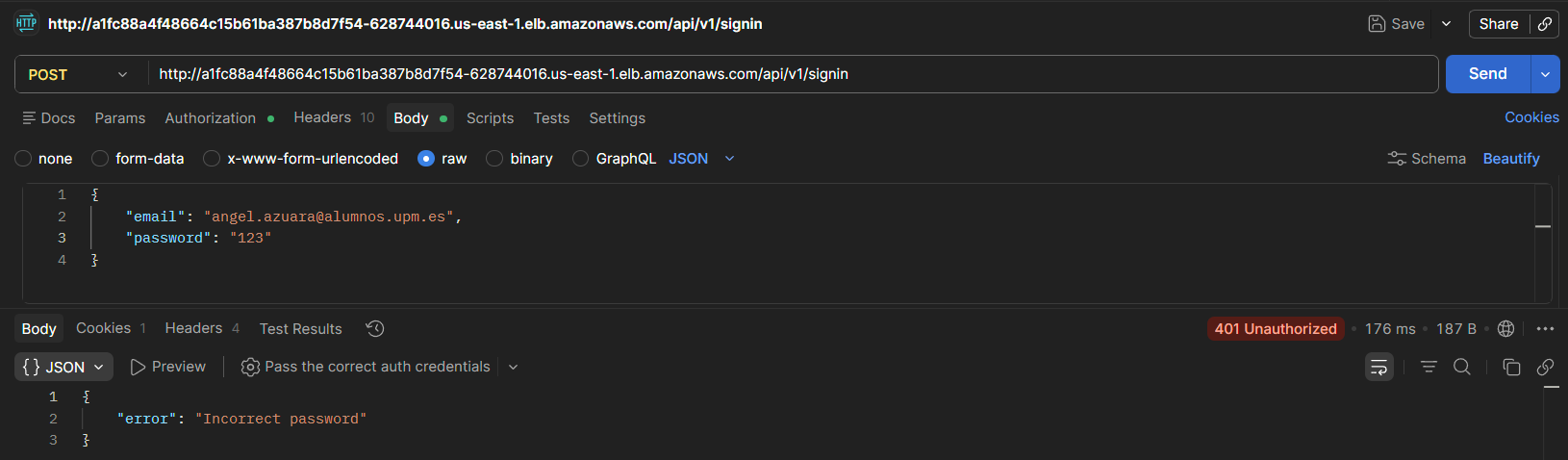
With incorrect credentials it returns an auth error, and without an active session it returns 401 Unauthorized.

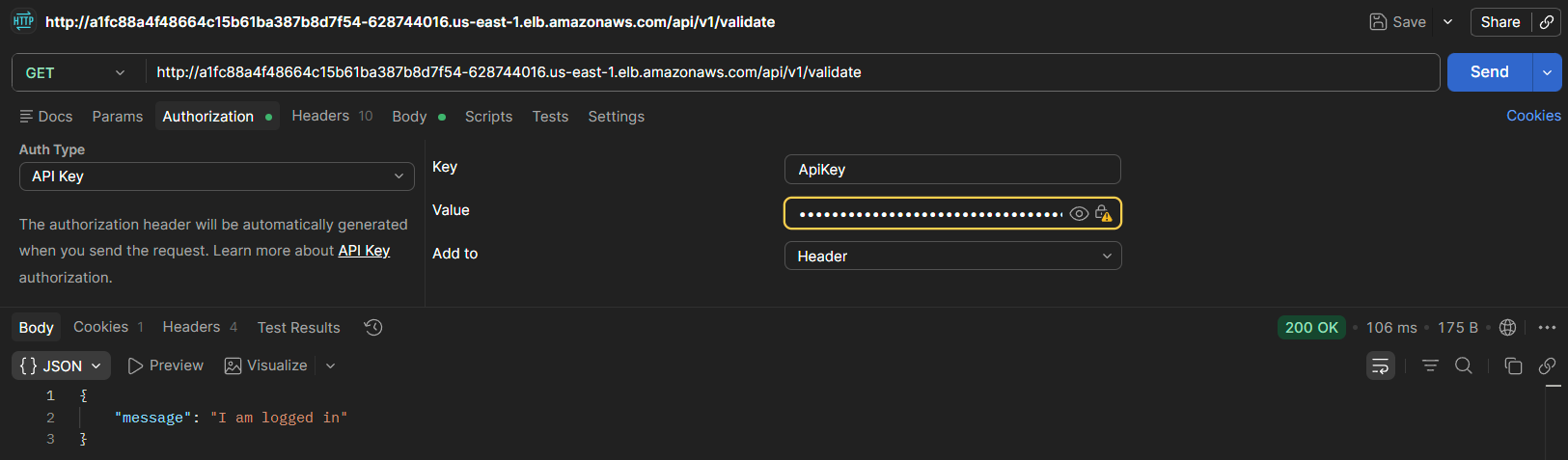
3.1.3 Endpoint /validate
Checks whether the user is authenticated via the session cookie.
3.1.4 Endpoint /jobs
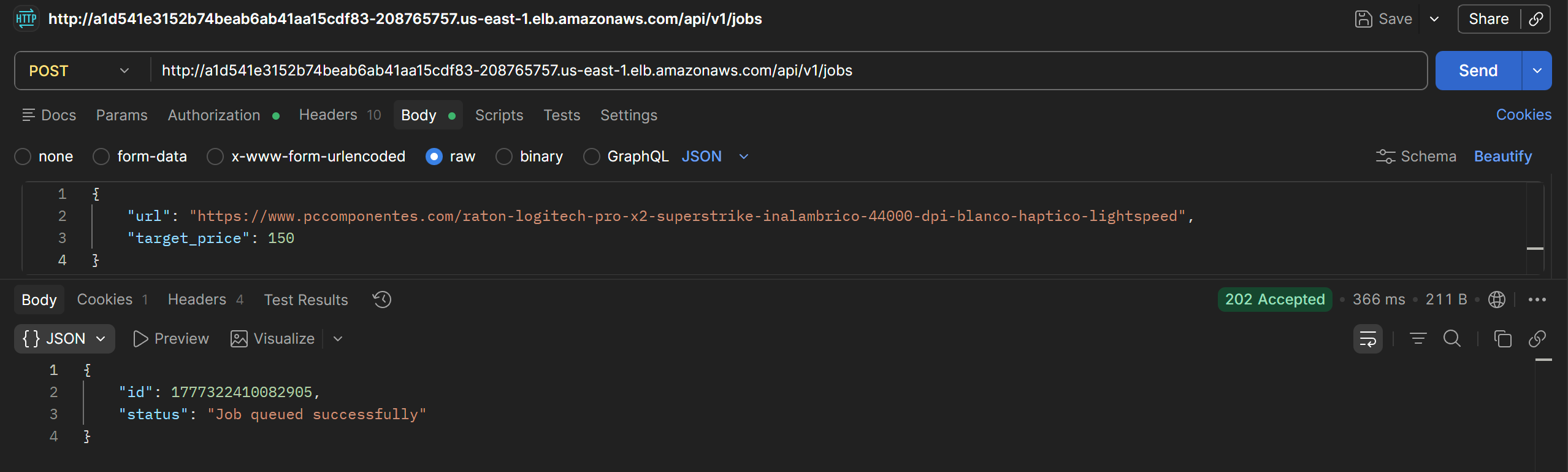
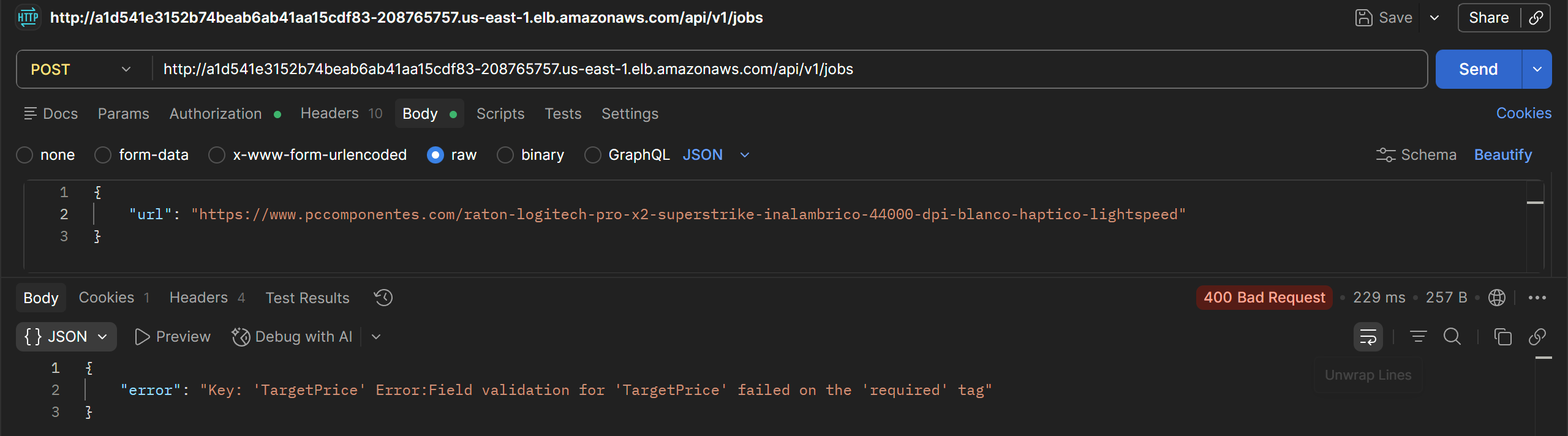
Allows creating, listing, and deleting jobs for the authenticated user.
When a job is created with a target price above the current product price, the system sends an email with the subject Price Alert, confirming the notification flow works correctly.
Missing parameters return a 400 Bad Request:
Listing jobs:
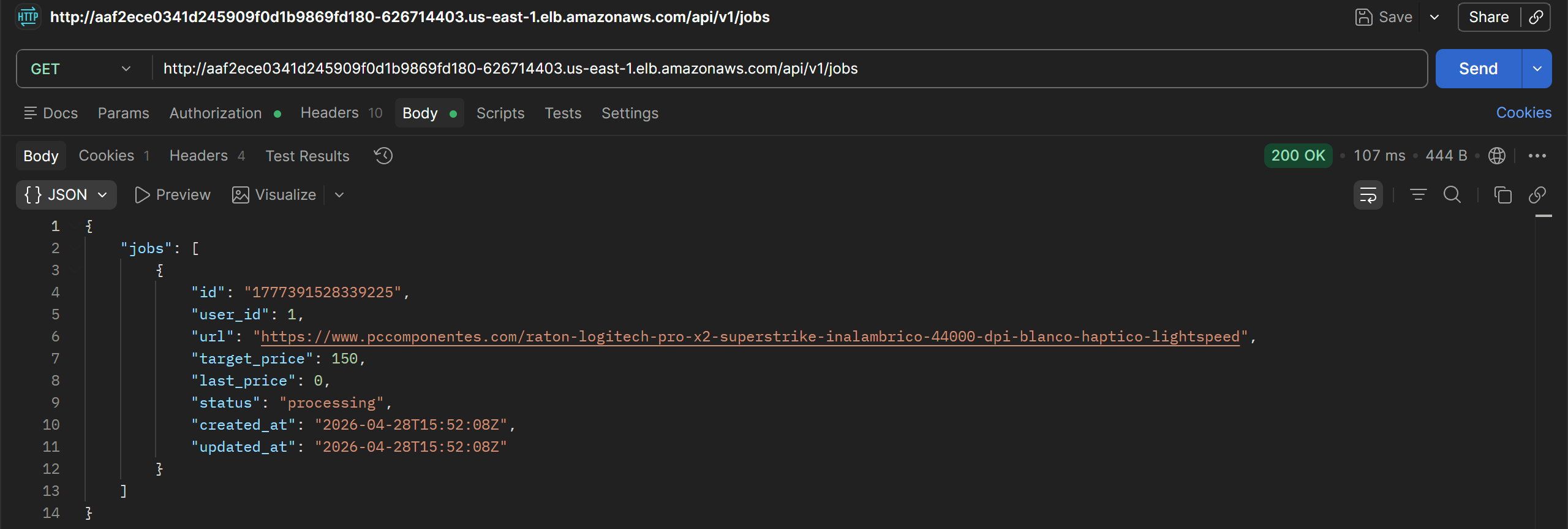
Deleting jobs:

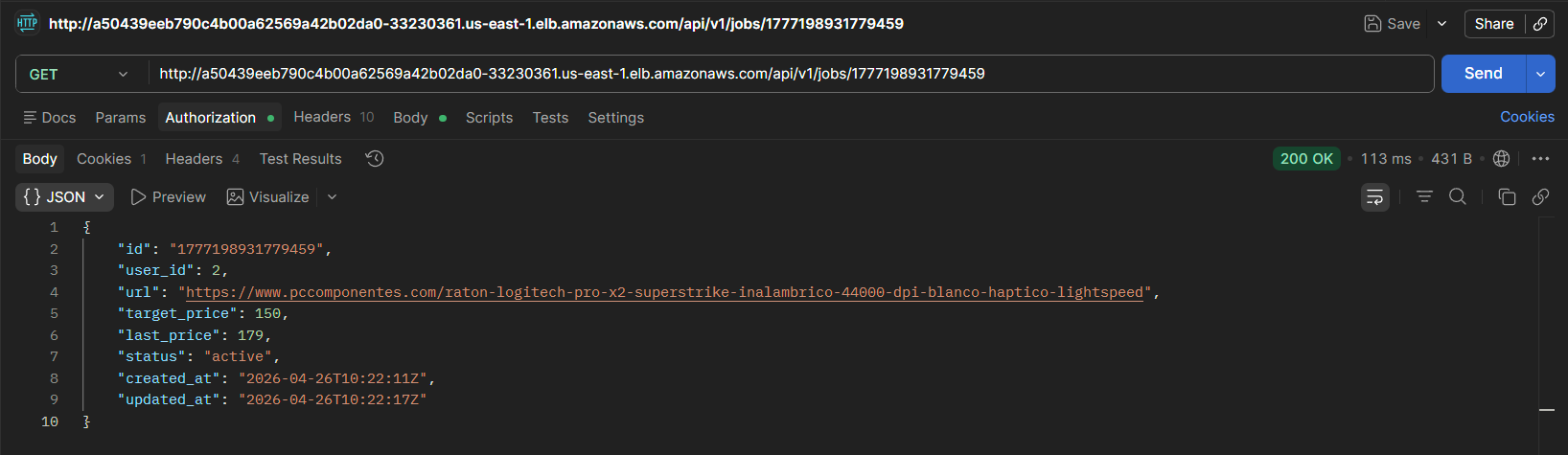
3.1.5 Endpoint /jobs/:id
Retrieves or deletes a specific job by its identifier. Returns 404 Not Found if it does not exist.

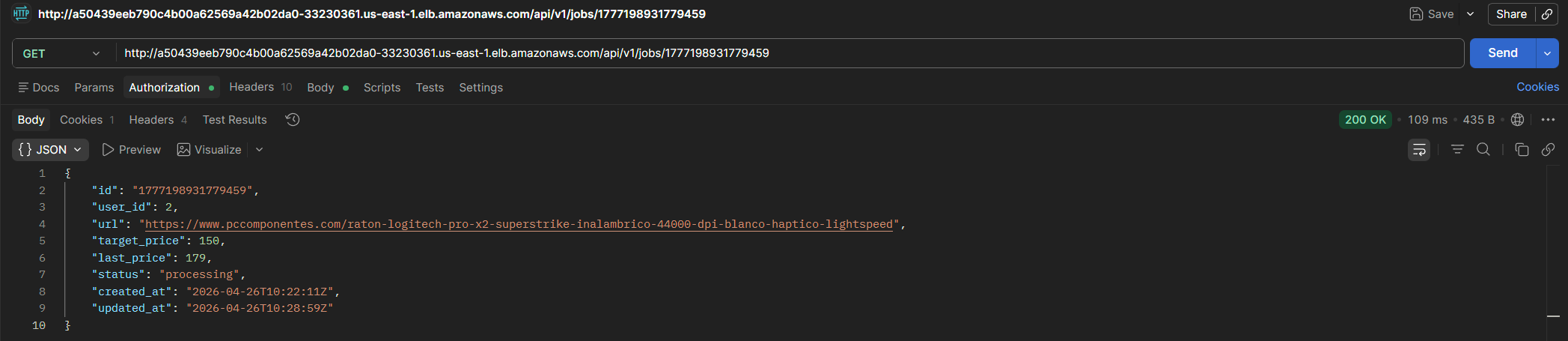
3.2 Asynchronous Job Processing
When a job is created, it is stored with pending status. Once processed by the scraper, the status changes to active and the last price is updated. At some point in between, processing status can be observed, indicating the scraper has read the job from the SQS queue.
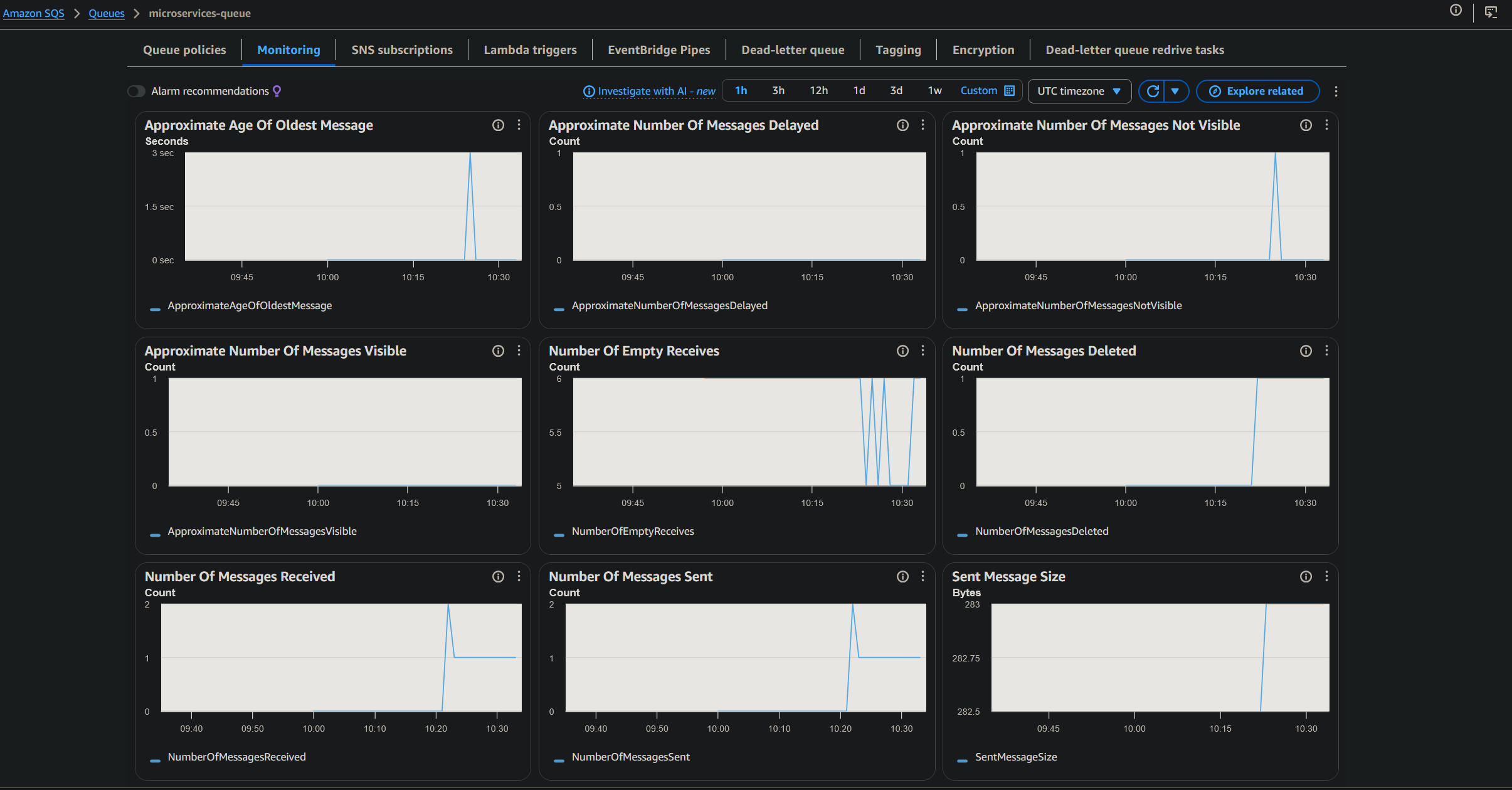
3.3 System Monitoring
AWS monitoring tools were used to validate the behavior of the asynchronous components.
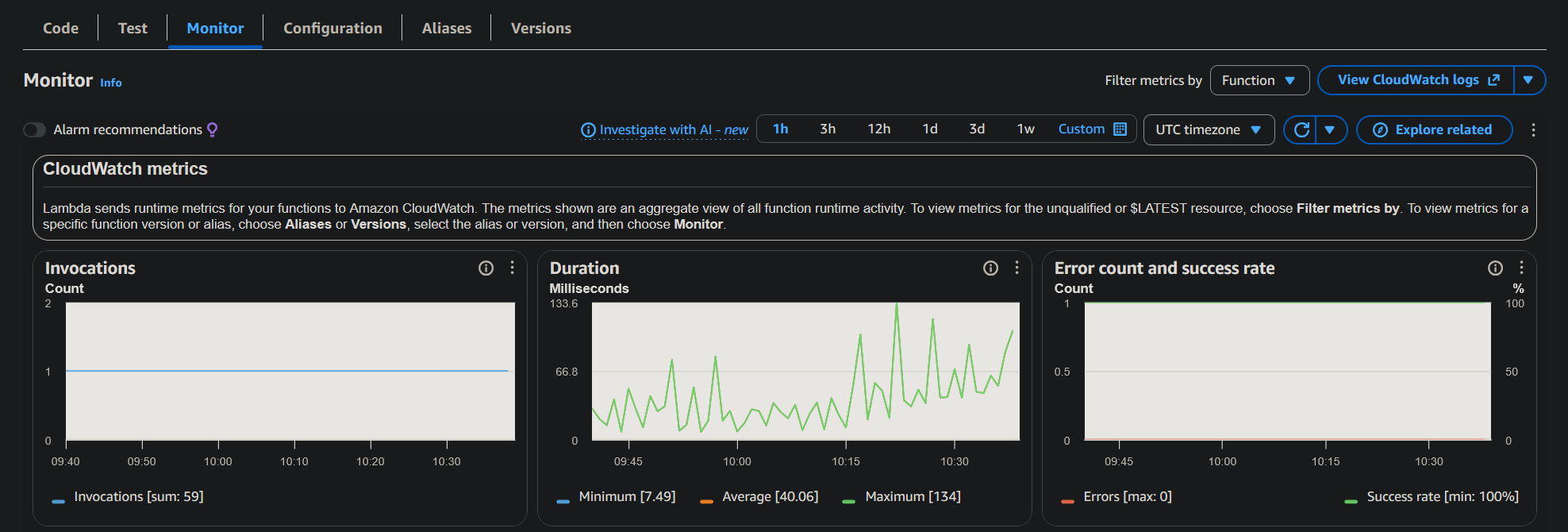
3.4 Infrastructure Validation
CloudWatch alarms were configured to monitor the state of the deployed resources.
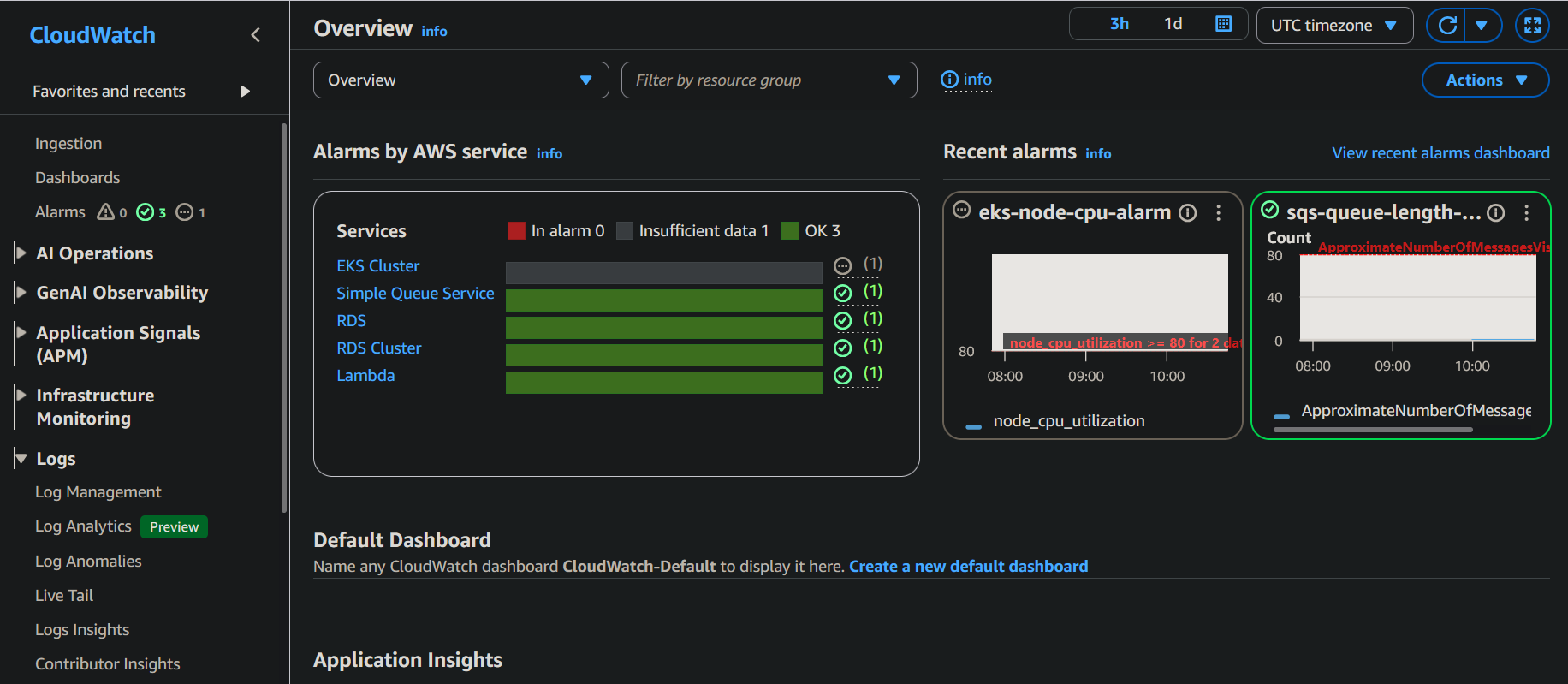
3.5 Deployment Automation
Pushing a commit to the repository triggers GitHub Actions to build and publish the new image. FluxCD detects the new version, updates the manifest (auto-commit from the Flux bot), and sends a Discord notification confirming cluster reconciliation.
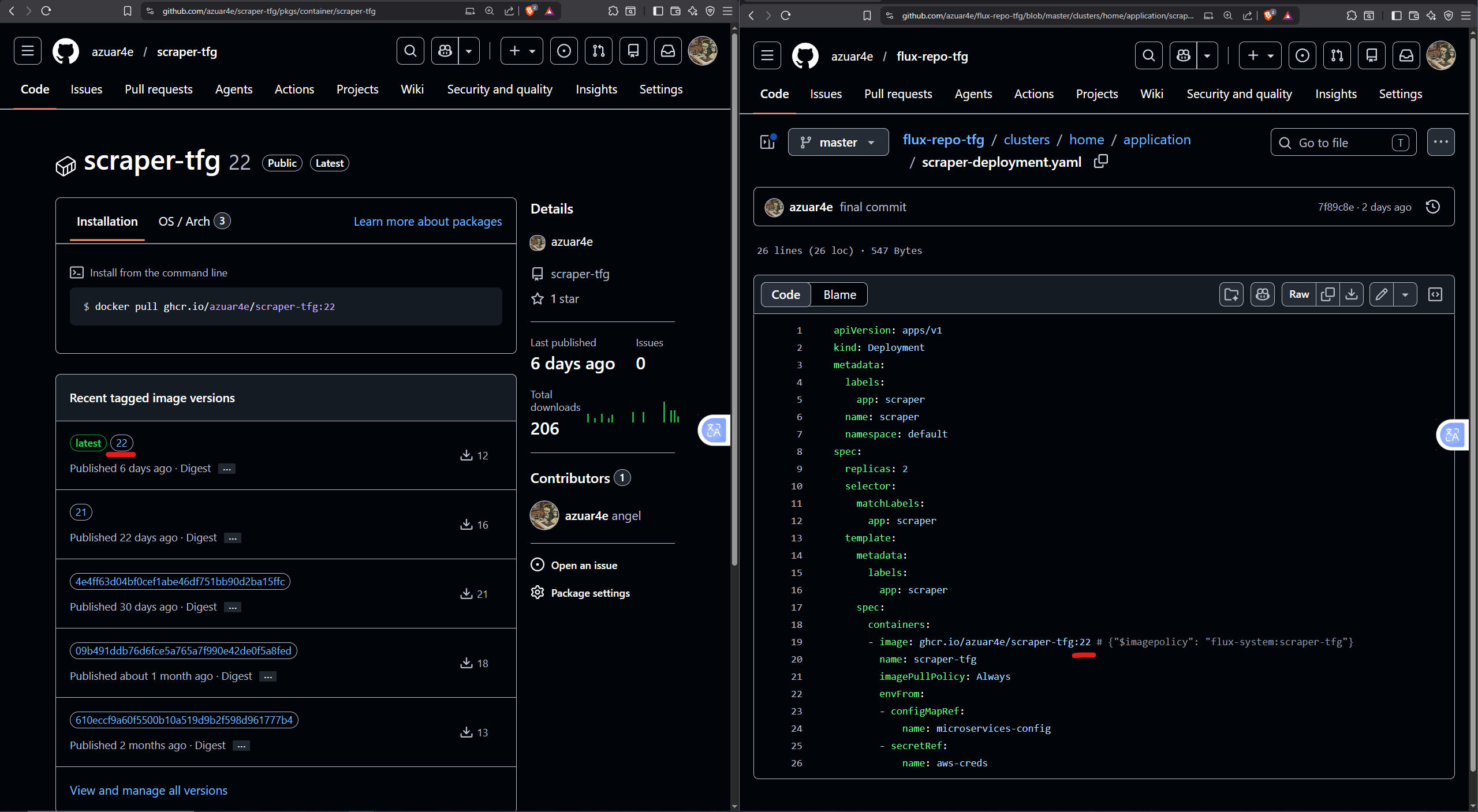
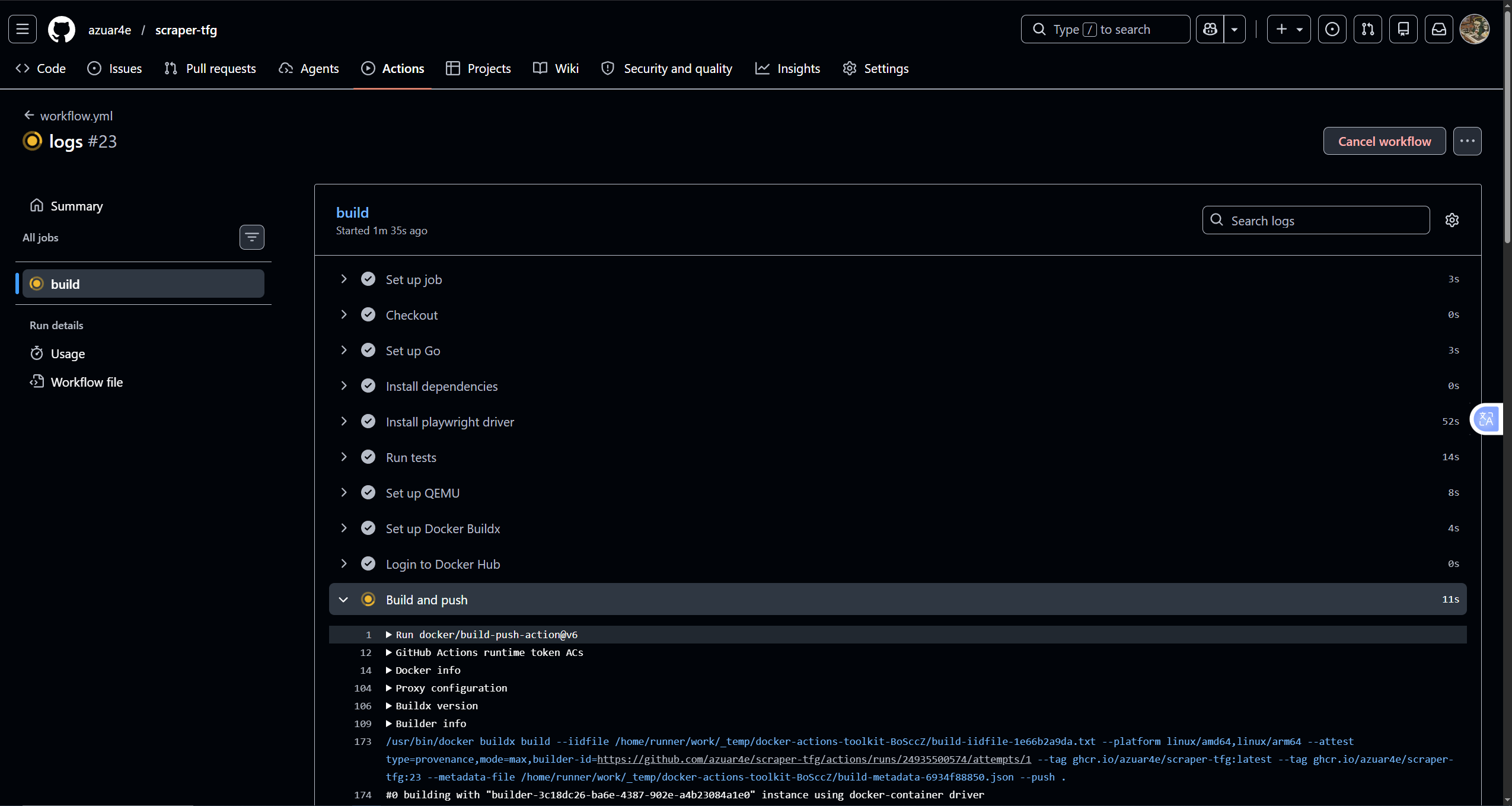
3.6 Load and Performance Testing
Once the system was functionally validated, load tests were run with k6 to analyze behavior under different demand levels.
As mentioned in the Scalability and Resources section, the scraper should ideally scale based on queue depth rather than CPU usage. These tests therefore primarily evaluate the API’s response capacity.
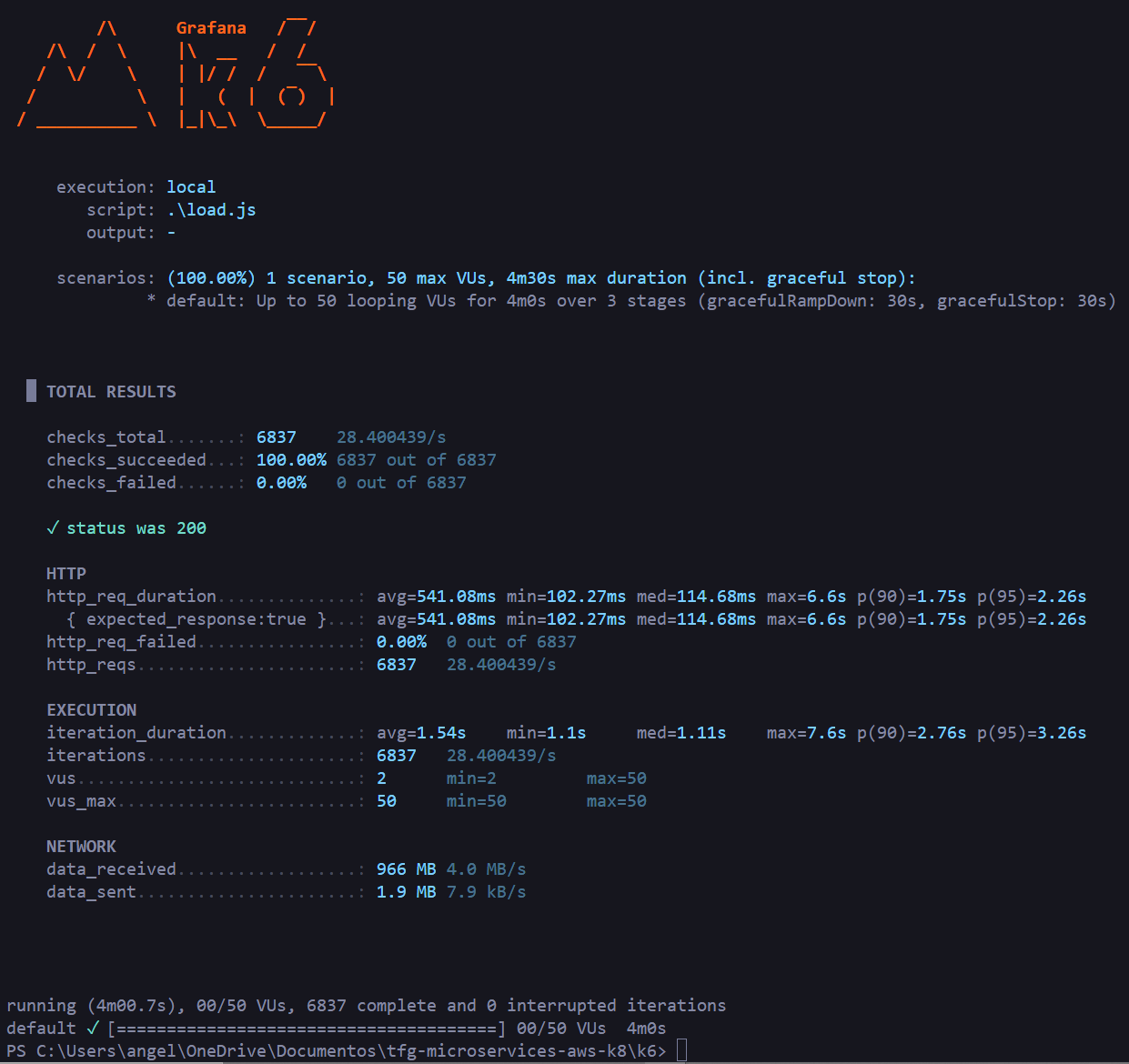
3.6.1 Load Test
50 concurrent virtual users for 4 minutes sending HTTP GET requests to /jobs:
| |
Result: 100% successful checks across 6,837 requests, mean latency 541ms, median 114ms, p(95) 2.26s.
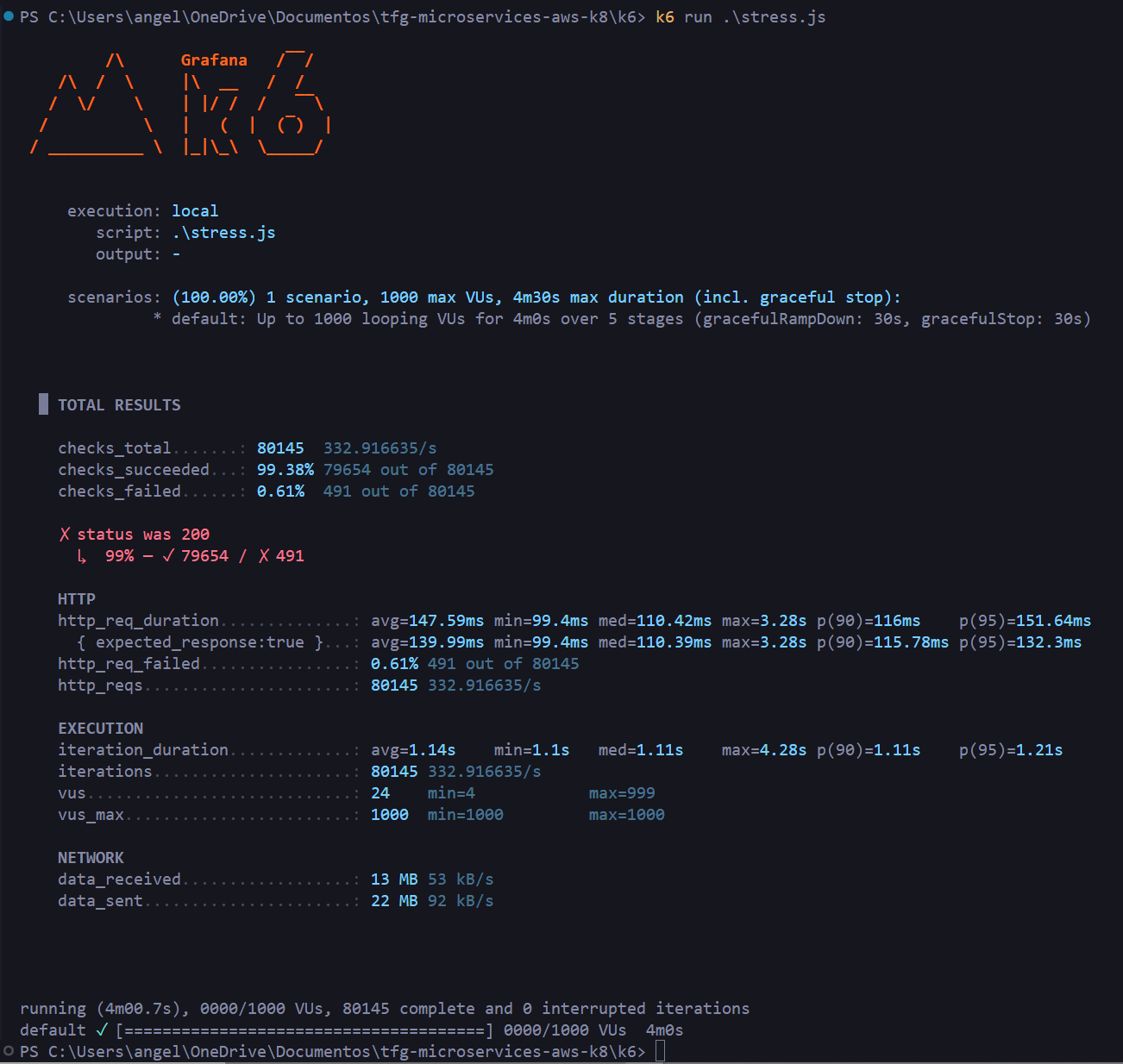
3.6.2 Stress Test
Progressive load scaling from 100 to 1,000 virtual users:
| |
Result: 80,145 requests at 333 req/s, mean latency 147ms, median 110ms. Only 0.61% failures (491 requests) at peak load with 1,000 concurrent VUs.
3.6.3 Spike Test
Sudden transition from 50 to 2,000 virtual users in 10 seconds:
| |
Result: 71.54% failure rate, all timeouts, mean latency 18.5s. The HPA does not have enough time to react to such an abrupt spike — the expected behavior for this type of test.
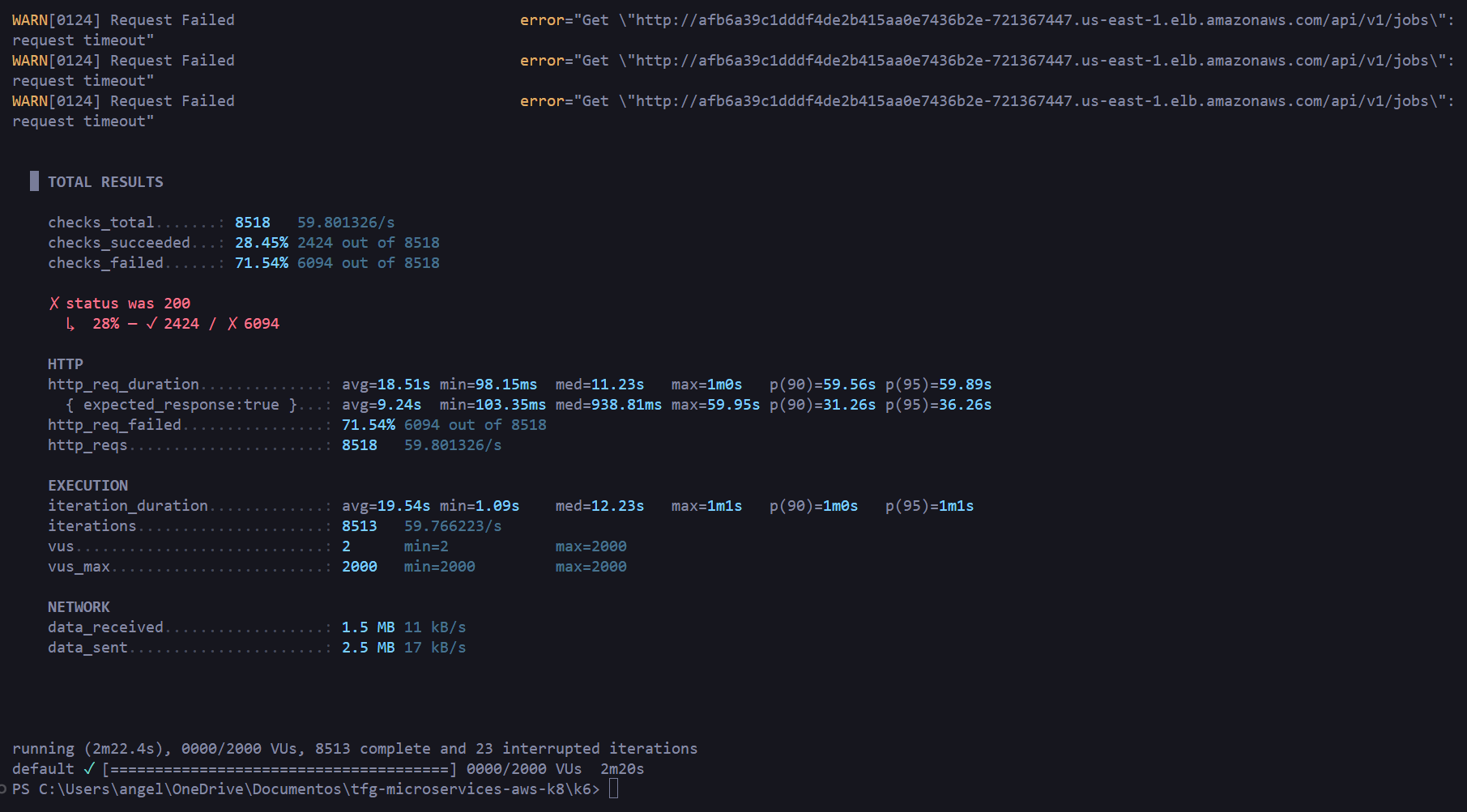
3.6.4 Summary
| Scenario | VUs | Requests | Error rate | Mean latency | P95 |
|---|---|---|---|---|---|
| Load (sustained) | 50 | 6,837 | 0.00% | 541ms | 2,260ms |
| Stress (progressive) | 1,000 | 80,145 | 0.61% | 147ms | 151ms |
| Spike (avalanche) | 2,000 | 8,518 | 71.54% | 18,510ms | >60,000ms |
4 Video DEMO
5 Conclusions
This project illustrates the importance of microservices-based architectures and the cloud-native approach in modern software development.
The entire application lifecycle was covered end-to-end: from technology stack selection, containerization, and service validation automated via GitHub Actions, through to deployment on an EKS cluster using a GitOps tool like FluxCD, where a repository serves as the single source of truth for the desired cluster state.
Infrastructure provisioning was also automated using Infrastructure as Code, allowing the environment to be declared, spun up, and torn down reproducibly, with state stored in an S3 backend.
All the code is available in the GitHub repositories:
👉 https://github.com/azuar4e/api-gateway-tfg
👉 https://github.com/azuar4e/scraper-tfg
Thanks for reading, see you next time. Take care! 👋
6 Appendix
| |