Traductor De Lenguajes
1 Introducción
En este artículo explico el funcionamiento de un compilador, desde el procesamiento del fichero fuente hasta la traducción a código objeto. Este post está basado en un trabajo universitario para la asignatura Traductores de Lenguajes. Todo el código fuente está disponible en mi repositorio de GitHub (enlace al final, en la sección Herramientas).
El traductor genera, a partir de un archivo de código escrito en el Lenguaje Boreal, previamente validado por el procesador, un archivo .ens con el código objeto del programa, escrito en el lenguaje ENS2001.
El proyecto se divide en dos partes principales:
- Procesador de lenguajes, escrito en Java, proporcionado por la asignatura y extendido por nosotros.
- Traductor de lenguajes, desarrollado desde cero en Python.
Nota: Esta implementación solo cubre:
- Las sentencias IF-THEN e IF-THEN-ELSE.
- El operador mínimo MIN.
- Los procedimientos PROCEDURE con paso de parámetros por valor y por referencia.
- Los operadores
*,ANDy=(comparación, no asignación).⚠️ El resto de operadores no están cubiertos.
⚠️ Tampoco se realiza ninguna optimización sobre el código objeto (ensamblador). ⚠️ Los materiales originales del Lenguaje Boreal y el procesador ENS2001 pueden no estar disponibles temporalmente. Este post se centra en mi implementación del compilador, no en la distribución de los materiales originales. Si necesitas consultarlos, puedes intentar acceder más adelante o buscar versiones archivadas.
2 Procesador de Lenguajes
El procesador de lenguajes es el responsable de validar que un fichero fuente no tenga errores de tipo léxico, sintáctico o semántico.
Este módulo se divide en cuatro etapas:
- Analizador léxico
- Analizador sintáctico
- Analizador semántico
- Generador de código intermedio, que en realidad pertenece al traductor pero forma parte del código del procesador.
Antes de comenzar, es importante conocer los siguientes conceptos:
- Tabla de símbolos: es la encargada de almacenar los identificadores de las variables, constantes, procedimientos, etc.
E.g.
| |
- Parse: es el encargado de almacenar el orden con el que se ejecutan las reglas de la gramática.
E.g.
| |
ascendente indica el tipo de analizador sintáctico utilizado.
- Tokens: puede ser cualquier cosa: un
for, un;, el nombre de una variable, etc. El archivo fuente es dividido en tokens, que son almacenados en otro fichero bajo este nombre.
E.g.
| |
- Por último, el tipo de procesador. En este caso, usamos uno ascendente, pero también existen descendentes, descendentes con tablas, etc.
2.1 Analizador léxico
Para los errores léxicos, utilizamos un autómata que recorre el fichero fuente carácter a carácter. A medida que se avanza, se van evaluando los estados del autómata y, si todo va bien, se genera un archivo de tokens como salida.
Si se encuentra algún símbolo que no encaja en el autómata, se considera un error léxico.
E.g. de un autómata:
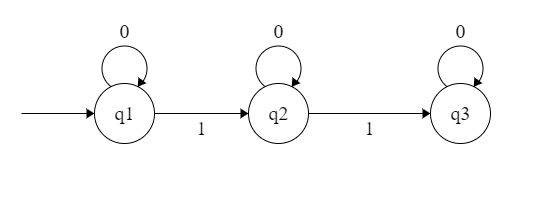
Un caso típico de error léxico es una cadena sin cerrar. La siguiente imagen muestra un autómata que reconoce cadenas entre comillas:
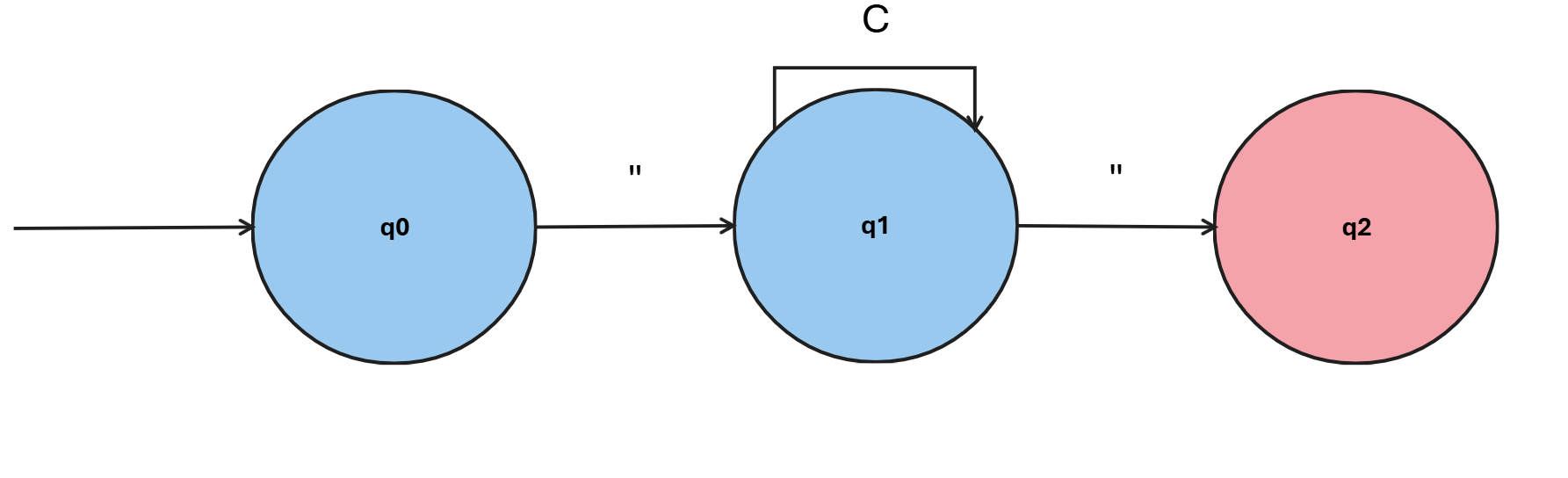
Aquí, C representa cualquier carácter. Para alcanzar el estado final y reconocer una cadena correctamente, necesitamos que termine con un ".
También se consideran errores léxicos situaciones como:
- Una cadena que supera la longitud máxima permitida
- Un número fuera de rango
- Caracteres no válidos en el lenguaje
Entre otros.
2.2 Analizador sintáctico
Para los errores sintácticos, se analizan las estructuras del lenguaje mediante reglas gramaticales. Estos errores aparecen cuando la secuencia de tokens no sigue la sintaxis esperada. Aquí entra los conceptos de first y follow. Para explicarlos, mostramos un fragmento de una gramática:
| |
Un terminal es un símbolo que aparece tal cual en el lenguaje fuente (;, if, var…).
Un no terminal representa una regla o construcción de la gramática (T, B, P…).
El conjunto first de un no terminal son todos los terminales con los que puede comenzar.
Por ejemplo, elfirst(W)sería:id,output,input,return,{(Begin).El conjunto follow de un no terminal son los terminales que pueden aparecer justo después de él en una derivación.
Por ejemplo, siXsiempre va seguido de;, entoncesfollow(X) = { ; }.
Si una regla puede derivar en lambda (vacío), su follow también incluye lo que podría venir tras ese punto en la producción.
e.g. en P → B P y P → lambda, como P puede ser vacío, follow(B) incluye lo que sigue a P, e incluso el símbolo de fin $.
Un error sintáctico se produce cuando el token actual no pertenece al conjunto first de la regla esperada.
Por ejemplo, si se espera una producción de W y el siguiente token es if (que no está en first(W)), se trata de un error.
Ejemplo típico: un
elsesin suif, o una expresión mal cerrada.
2.3 Analizador semántico
Para los errores semánticos, utilizamos acciones semánticas, en las que se definen cosas como:
- Herencia de atributos
- Inserciones en la tabla de símbolos
- Validaciones de tipos
Por ejemplo, en una regla como W → output E ;, podríamos tener una acción semántica del estilo { W.tipo := E.tipo }, que asigna a W el tipo de E.
En el código, esto se reflejaría evaluando ese caso y actualizando la pila de atributos.
Un error semántico típico sería que el tipo heredado no coincida con el esperado.
2.4 Generador de código intermedio
Volviendo al traductor, el generador de código intermedio es una extensión del procesador en la que definimos nuevas acciones semánticas para poder generar el fichero con el código intermedio, en este caso, en el formato de un fichero de cuartetos definido por la asignatura.
Para esto, en nuestra implementación definimos 2 nuevas clases, gci.java y cuarteto.java.
En la primera definimos las siguientes funciones:
emite, que es la que genera los cuartetos:
| |
nuevatemp, que crea una nueva variable temporal del tipo especificado y la inserta en la tabla de símbolos:
| |
nuevaetiq, que crea una nueva etiqueta utilizada para los saltos condicionales e incondicionales:
| |
En la clase cuarteto definimos el objeto cuarteto y un método toString para su representación:
| |
En cuanto a las acciones semánticas para la generación de código intermedio, se definen en la clase ASem.java junto a las acciones del propio analizador semántico.
A continuación un fragmento de código para la acción processRule(94, "Z -> id LL");
| |
La acción semántica se divide en dos ramas:
Si no hay parámetros (
llAtb.getLongs() == 0):- Si
ides un procedimiento → emitirCALL. - Si es una variable → crear tupla con su ámbito (local o global) y desplazamiento en la tabla de símbolos, y asignarlo a
res.setLugar()para que se herede por el resto del arbol y sea accesible en otras reglas.
- Si
Si hay parámetros:
- Emitir los parámetros uno a uno según tipo y paso por valor/referencia.
- Emitir
CALL_FUN,CALL_FUN_CADoCALLsegún el tipo de retorno. En este caso solo puede serCALLya que el traductor está diseñado únicamente para procedimientos (sin valor de retorno).
reses un objeto de la clase atributos y es lo que retorna el método de la acción. Las acciones también reciben objetos de la clase atributos que se obtienen desde la pila de atributos del analizador semántico.
3 Traductor de lenguajes
Una vez validado el archivo fuente, se nos generan los archivos tokens.txt, parse.txt, errores.txt, ts.txt y adicionalmente, el archivo cuartetos.txt. A continuación, el generador de código objeto, en base al fichero de cuartetos, genera un archivo .ens.
Como hemos hecho con anterioridad, antes de adentrarnos en el código debemos saber:
Que un registro de activación (RA) es una zona de memoria consecutiva en la que se almacena la información de activación de un subprograma (cada uno tiene el suyo propio).

El estado de la máquina (EM) es el estado antes de llamar a un subprograma.
El puntero de control (pc) apunta al RA del subprograma llamador. Se usa al finalizar el subprograma.
El puntero de acceso (pa) apunta al registro de activacion del subprograma donde está declarado el subprograma actual. Si
besta definido ena, el pa debapunta aa. Se utiliza para acceder a variables no locales cuando hay anidamiento de funciones.
3.1 Ficheros empleados
En esta implementación hacemos uso de tres ficheros:
_ens.py: maneja la creación y escritura del archivo.ens._gco.py: archivo principal; traduce cada cuarteto a instrucciones.ens._calcprev.py: calcula tamaños de RA’s y zona de datos estáticos (globales).
3.2 Funcionamiento
_ens.py: este módulo contiene una única función que abre el archivo .ens en modo escritura y añade líneas según sea necesario:
| |
_calcprev.py: Este script recorre la tabla de símbolos (ts.txt) para calcular:
El tamaño de la zona de datos estáticos.
Los tamaños de cada registro de activación (RA).
Las referencias necesarias para parámetros por referencia.
Utilizamos dos funciones auxiliares, una para leer cada línea de la tabla de símbolos y otra para obtener el tamaño de cada tipo.
| |
Luego en el main() hacemos un bucle que:
Lee línea a línea la tabla de símbolos.
Para la tabla local:
- Calcular el tamaño del RA sumando los tamaños obtenidos con
reserva(...). - Registrar los desplazamientos de los parámetros pasados por referencia.
- Calcular el tamaño del RA sumando los tamaños obtenidos con
Para la tabla global:
Suma tamaños de variables globales.
Suma el tamaño del retorno si es una funciones/procedimientos.
Finalmente, genera las directivas de inicio de memoria y las etiquetas
EQUpara cada RA:
| |
Nota: La variable
cadfinalno se escribe aquí porque su contenido se añade al final del fichero.ens.
Por último tenemos _gco.py, el archivo principal. A continuación pongo un extracto para entender su funcionamiento:
| |
Tenemos una sección con los patrones para detectar cada posible cuarteto, para esto hacemos uso de la librería re.
También usamos estos patrones para extraer desplazamientos, nombres, espacios y detectar el programa principal.
| |
En cuanto a las funciones, utilizamos las siguientes:
leer: utilizada para leer cada cuarteto.
| |
declarar_cads: nos permite declarar los literales de cadenas al final del fichero de salida. Al final del bucle principal, llamamos a esta funcion con el atributocadenaNone ywritecomoTrue.
| |
leer_cadena_ens: con esta función podemos pasar caracter a caracter la cadena declarada a un registro, o de un registro a otro. Esto es fundamental ya que a diferencia de con los enteros, para las cadenas tenemos que mover todo su contenido caracter a caracter.
| |
paramcad: análoga a la anterior, esta se usa únicamente cuando el parámetro de un subprograma es una cadena.
| |
transformar_dir: encargada de mover las direcciones de memoria pasadas como parámetros a los registros correspondientes. Estas pueden ser entre una y tres. Básicamente, recibe algo como{VAR_GLOBAL, 3}y esto mueve lo que hay en la dirección#3[.IY]a un registro comoR2. Esto porque es global, si fuera local sería#3[.IX].
| |
Por último, el buble principal, que es el encargado de llamar a las funciones anteriores, y de iterar sobre cada cuarteto recibido. Dado que este bucle ocupa 600 líneas, pongo el comienzo para que se vea claro su funcionamiento.
| |
Como se puede observar, es un bucle muy sencillo en el que vamos evaluando cada caso y generando el código objeto correspondiente.
4 Ejecución
En esta sección se explica cómo ejecutar el código generado por el traductor, y se prueban diferentes ejemplos para entender su funcionamiento.
Nota: Solo se cubre la explicación para Windows, ya que en Linux el ensamblador no tiene interfaz y resulta menos didáctico.
4.1 Prerequisitos
- Asegurarse de que se haya compilado el proyecto (ver sección Uso).
- Fichero
codobj.ensgenerado (código objeto).
4.2 Descarga
Para ello tenemos que descargarnos el ensamblador (disponible en la sección Herramientas). Al descomprimir el archivo, obtenemos una carpeta ENS2001-Windows como la siguiente:
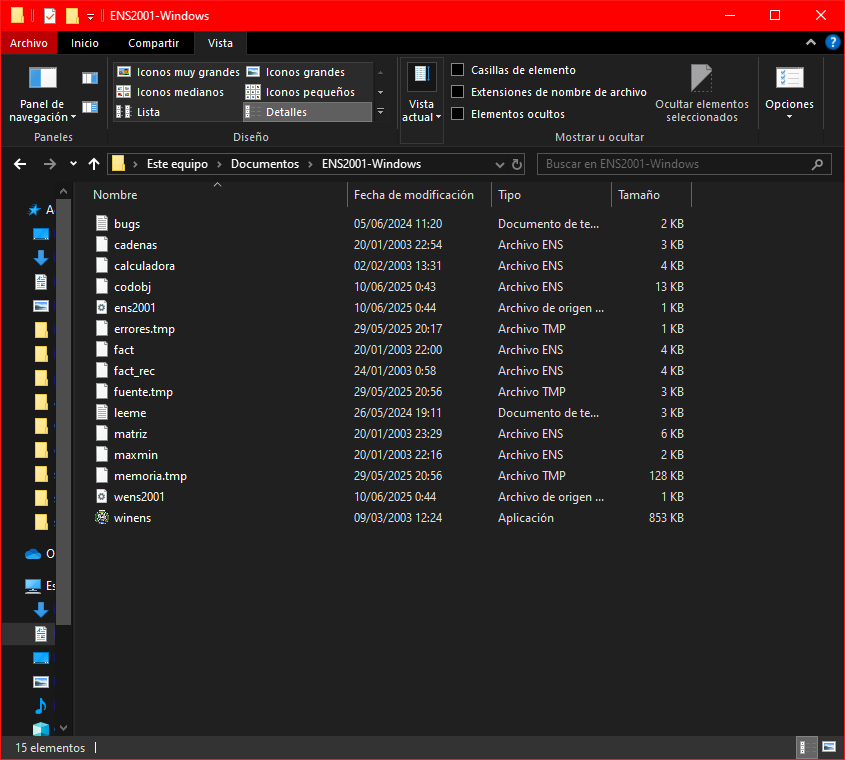
A excepción del fichero codobj.ens, que es el que vamos a ensamblar, el resto de archivos vienen por defecto. Se incluyen algunos ejemplos y dos ficheros que se recomienda leer: leeme.txt y bugs.txt.
4.3 Ensamblador
El ensamblador es el ejecutable que viene seleccionado en la captura de arriba (winens).
Una vez ejecutado, veremos una interfaz como la siguiente:
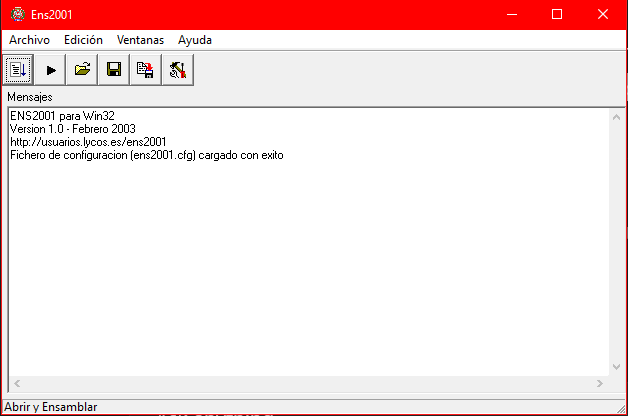
Para ver con claridad lo que va haciendo el ensamblador se recomienda abrir las siguientes ventanas:
La ventana del código fuente muestra el orden en el que se ejecutan las instrucciones del código objeto. En este caso como aun no se ha cargado ningun archivo, están todas las direcciones en
NOP.
La ventana de registros muestra el estado de los registros de la máquina.
La ventana de la pila muestra el contenido de la pila de datos.
Para cargar el archivo codobj.ens hacemos Archivo > Abrir y Ensamblar. Si todo va bien, nos dirá que ha sido ensamblado correctamente:
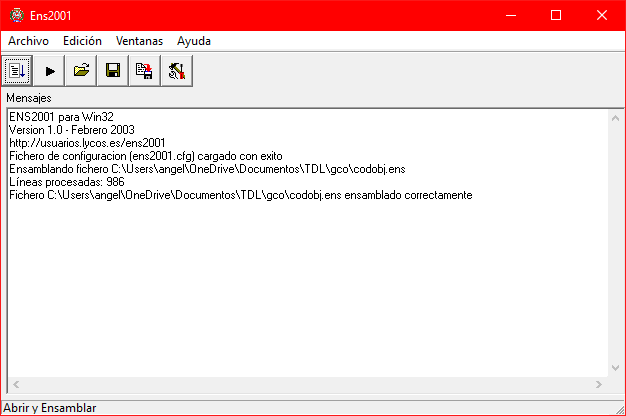
Ahora ya estamos listos para ejecutar el ensamblador. Al darle al ▶️ se ejecutará el ensamblador y nos mostrará el resultado. Si nuestro código ejecuta funciones de escritura en consola, esta se abrirá. En nuestro caso hemos ensamblado el fichero expr.txt (disponible en el repositorio de GitHub), y el resultado es el siguiente:
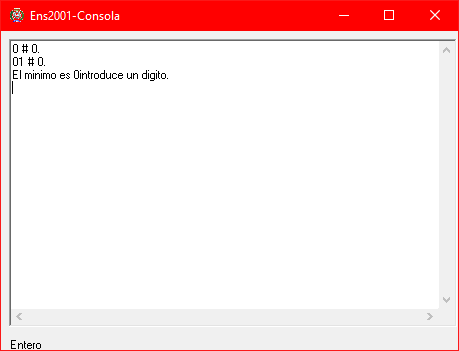
Introducimos un dígito como nos pide y le damos al enter.
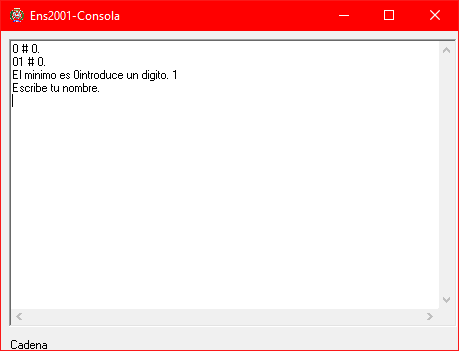
Escribimos nuestro nombre:
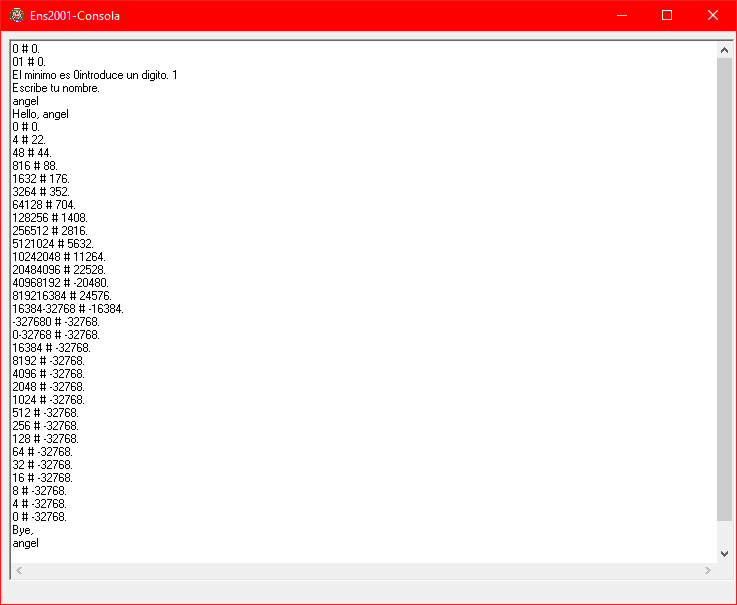
Y tras esto, el programa finaliza su ejecución correctamente.
5 Uso
En esta sección se detallan los pasos necesarios para instalar las dependencias, compilar el proyecto y ejecutar cada componente.
5.1 Instalación de dependencias
Para instalar la biblioteca del procesador (ts-lib.jar) en el repositorio local de Maven, ejecuta el siguiente comando:
| |
O si estás en Linux o macOS:
| |
5.2 Compilación del procesador
Una vez instalada la librería, genera el ejecutable del procesador con:
| |
5.3 Ejecución del procesador
Después de compilar, puedes ejecutar el procesador con el siguiente comando (sustituyendo la ruta por la del archivo Boreal):
| |
5.4 Ejecución del traductor
Desde la carpeta gco/, donde se encuentra el ejecutable del traductor, ejecuta:
| |
O si estás en Linux o macOS:
| |
Esto generará todos los archivos del procesador, así como el fichero cuartetos.txt (código intermedio) y codobj.ens (código objeto).
5.5 Ejecución del código objeto
Para ejecutar el archivo .ens, es necesario descargar el ensamblador (disponible en la sección Herramientas), compilarlo y ejecutarlo con el fichero codobj.ens generado.
6 Herramientas
Tanto el procesador de lenguajes como los ensambladores simbólicos para ensamblar el código objeto (ENS2001) se encuentran en el siguiente enlace:
Podéis encontrar el código fuente de esta implementación en mi repositorio de GitHub:
7 Conclusión
El proyecto es una gran oportunidad para aprender y profundizar sobre el funcionamiento de un compilador. Aunque este esta basado en un lenguaje y un ensamblador que en el día a día no se utilizan, nos sirve como ejemplo didáctico y sencillo para explicar los conceptos clave.
Nuevamente el código fuente lo podeís encontrar en mi repositorio de GitHub.
Have a nice life! 👋